Hello everyone,
I'm experiencing a random "IO Error" that causes my two Windows Server 2025 Data Center VMs to randomly halt (yellow triangle in Proxmox). A reset/reboot resolves the issue temporarily.
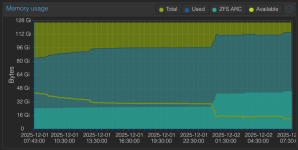
My environment details are below. I suspect a potential conflict with my configuration, possibly related to I/O or the high RAM usage.
Node and Storage
Node: Proxmox VE 9.0.11 on Linux 6.14 kernel.
CPU: Intel Xeon E-2288G (16C).
RAM Usage: High (approx. 89% of 31 GiB).
Storage: ZFS pool built on two 960 GB Samsung NVMe SSDs (S.M.A.R.T. OK, low wearout).
Repo Status: Non production-ready repository enabled.
Windows VM Configuration
Both Windows Server 2025 VMs use the following critical settings:
Setting Value
SCSI Controller VirtIO SCSI single
Disk Image RAW format on ZFS
I/O Settings aio=io_uring, cache=writeback, discard=on, iothread=1, ssd=1
Memory 13 GiB and 6 GiB respectively
Processors Host CPU type
BIOS OVMF (UEFI)
Has anyone encountered this specific IO Error with this configuration (especially VirtIO/ZFS/IO_URING) on recent Proxmox versions?
My apologies, I accidentally posted this twice
I'm experiencing a random "IO Error" that causes my two Windows Server 2025 Data Center VMs to randomly halt (yellow triangle in Proxmox). A reset/reboot resolves the issue temporarily.
My environment details are below. I suspect a potential conflict with my configuration, possibly related to I/O or the high RAM usage.
Node and Storage
Node: Proxmox VE 9.0.11 on Linux 6.14 kernel.
CPU: Intel Xeon E-2288G (16C).
RAM Usage: High (approx. 89% of 31 GiB).
Storage: ZFS pool built on two 960 GB Samsung NVMe SSDs (S.M.A.R.T. OK, low wearout).
Repo Status: Non production-ready repository enabled.
Windows VM Configuration
Both Windows Server 2025 VMs use the following critical settings:
Setting Value
SCSI Controller VirtIO SCSI single
Disk Image RAW format on ZFS
I/O Settings aio=io_uring, cache=writeback, discard=on, iothread=1, ssd=1
Memory 13 GiB and 6 GiB respectively
Processors Host CPU type
BIOS OVMF (UEFI)
Has anyone encountered this specific IO Error with this configuration (especially VirtIO/ZFS/IO_URING) on recent Proxmox versions?
My apologies, I accidentally posted this twice
Last edited:

")