Guten Tag!
Ich habe einen einzelnen node laufen, auf welchen mehrere vm´s mit linux ubuntu laufen.
Seit 4 Tagen habe ich jetzt das Problem, dass ohne Ankündigung einfach ein "reboot" durchgeführt wird. Auf einmal ist alles tot und mein pve1 fährt wieder normal hoch.
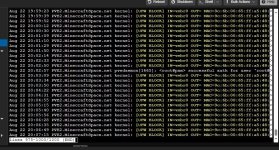
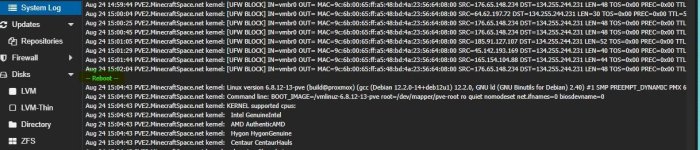
Im syslog steht dann bis zum --reboot-- nichts auffälliges, meistens steht drinnen, dass von ufw eine IP geblockt wurde, aber nichts wo auf einen Fehler zeigen würde.
Habe dann erstmal Proxmox und alle vm´s einem update unterzogen und pve1 läuft aktuell mit der Version 8.4.11
Der Server steht im Rechenzentrum, somit habe ich Kontakt mit dem Support aufgenommen. Die haben erstmal ein Biosupdate durchgeführt und angeblich im Bios Werte verändert, welche eine Verbesserung oder Behebung meines Problems bringen sollte.
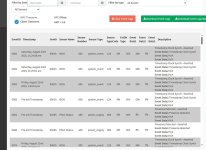
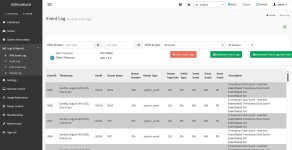
Keine 14 Stunden später, der Server ist wieder tot und im Log steht nur "--reboot--" drin.
Support wieder angeschrieben mit einem screen aus den logs und dann haben sie die Hardware genauer angeschaut und angeblich einen defekten Lüfter getauscht, da beim testen die Temperatur der CPU zu hoch war.
Server ging wieder online und keine 7 Stunden später war der Server wieder tot - CPU Temperatur lag im Durchschnitt zwischen 55 - 70°C
Habe das Phänomen, dass das System ab und an, einfach einen "--reboot--" macht, schon immer gehabt. Da trat es aber nur alle 7 bis 20 Tage total unregelmäßig auf. Ich hab mir gedacht, aufgrund meiner laienhaften Kenntnisse, wird schon irgendwo was nicht passen. Aber seit dem es extrem geworden ist, was von heute auf morgen passiert ist und NICHTS am Server verändert wurde, ist es verdammt ärgerlich. Zu beginn kam ein "--reboot--" schon alle 30 bis 60 Minuten, also am ersten Tag des Problems gute 20 mal.
Vielleicht kann mir jemand weiterhelfen um heraus zu finden, ob es an Proxmox oder der Hardware liegt?
Für jede Hilfe bin ich sehr dankbar.
Wünsche Euch noch einen schönen Tag.
LG Stefan
Ich habe einen einzelnen node laufen, auf welchen mehrere vm´s mit linux ubuntu laufen.
Seit 4 Tagen habe ich jetzt das Problem, dass ohne Ankündigung einfach ein "reboot" durchgeführt wird. Auf einmal ist alles tot und mein pve1 fährt wieder normal hoch.
Im syslog steht dann bis zum --reboot-- nichts auffälliges, meistens steht drinnen, dass von ufw eine IP geblockt wurde, aber nichts wo auf einen Fehler zeigen würde.
Habe dann erstmal Proxmox und alle vm´s einem update unterzogen und pve1 läuft aktuell mit der Version 8.4.11
Der Server steht im Rechenzentrum, somit habe ich Kontakt mit dem Support aufgenommen. Die haben erstmal ein Biosupdate durchgeführt und angeblich im Bios Werte verändert, welche eine Verbesserung oder Behebung meines Problems bringen sollte.
Keine 14 Stunden später, der Server ist wieder tot und im Log steht nur "--reboot--" drin.
Support wieder angeschrieben mit einem screen aus den logs und dann haben sie die Hardware genauer angeschaut und angeblich einen defekten Lüfter getauscht, da beim testen die Temperatur der CPU zu hoch war.
Server ging wieder online und keine 7 Stunden später war der Server wieder tot - CPU Temperatur lag im Durchschnitt zwischen 55 - 70°C
Habe das Phänomen, dass das System ab und an, einfach einen "--reboot--" macht, schon immer gehabt. Da trat es aber nur alle 7 bis 20 Tage total unregelmäßig auf. Ich hab mir gedacht, aufgrund meiner laienhaften Kenntnisse, wird schon irgendwo was nicht passen. Aber seit dem es extrem geworden ist, was von heute auf morgen passiert ist und NICHTS am Server verändert wurde, ist es verdammt ärgerlich. Zu beginn kam ein "--reboot--" schon alle 30 bis 60 Minuten, also am ersten Tag des Problems gute 20 mal.
Vielleicht kann mir jemand weiterhelfen um heraus zu finden, ob es an Proxmox oder der Hardware liegt?
Für jede Hilfe bin ich sehr dankbar.
Wünsche Euch noch einen schönen Tag.
LG Stefan