This is my first post, hi everyone!
I have a 3 node PVE cluster which works very well except for one single thing: VM are randomly going crazy.
What I mean with crazy?
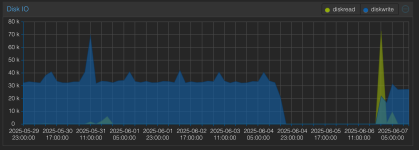
- Lost of IP address (and network traffic)
- No more disk activity
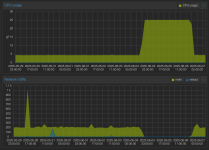
- CPU goes up to 25% and stay fixed at that value
(see attachment)
Considerations
- PVE hosts are not logging anything about the event
- the VM has nothing about the event in the logs because it's like the storage has ben pulled from the machine, so no chance to write anything about it
- this happens with any kind of backend I tried (Ceph, ZFS, local LVM on EXT4)
- it's totally random, can happen twice in a week as well as once in 3 months
- all the affected VM are based on Debian 12 (various releases, it' happening since 6+ months, last time this week, and I'm updating the OS every month more or less)
- I started the cluster with 8.2.x I think (maybe even 8.1.x), but updating to newer version never helped, I'm now at 8.3.2
- the cluster uses mixed nodes: #1 EPYC Rome, #2 XEON Scalable Gen. 2 #3 Xeon 22xx and it's happening to VM on all of them...
My question is not much a request of help to investigate this, but just a general question to understand if this is something kind of known?
Is it happening only to me or others have experienced a similar problem?
Because it's kind of a non-negligible problem I think...
I have a 3 node PVE cluster which works very well except for one single thing: VM are randomly going crazy.
What I mean with crazy?
- Lost of IP address (and network traffic)
- No more disk activity
- CPU goes up to 25% and stay fixed at that value
(see attachment)
Considerations
- PVE hosts are not logging anything about the event
- the VM has nothing about the event in the logs because it's like the storage has ben pulled from the machine, so no chance to write anything about it
- this happens with any kind of backend I tried (Ceph, ZFS, local LVM on EXT4)
- it's totally random, can happen twice in a week as well as once in 3 months
- all the affected VM are based on Debian 12 (various releases, it' happening since 6+ months, last time this week, and I'm updating the OS every month more or less)
- I started the cluster with 8.2.x I think (maybe even 8.1.x), but updating to newer version never helped, I'm now at 8.3.2
- the cluster uses mixed nodes: #1 EPYC Rome, #2 XEON Scalable Gen. 2 #3 Xeon 22xx and it's happening to VM on all of them...
My question is not much a request of help to investigate this, but just a general question to understand if this is something kind of known?
Is it happening only to me or others have experienced a similar problem?
Because it's kind of a non-negligible problem I think...
")

