Since I am in the process of deciding the most suitable block size for my VMs (90% ofthem will be Win Servers) as well (I also have a Raid 10 created with 4 drives), I was convinced I had to use 4k in order to avoid the padding issue. Now I noticed that also the raid type comes into the equation and the number of disks participating on that raid?.
So I have to add more notes to my mini guides for future reference. I don t get why 8k is the minimum (since it is the default one i would be on the safe side-assuming that this was the best possible blocksize) What would happen for instance if the block was 4k on that raid (how that split would happen)? ... and what if that raid10 was based on 8 drives and not 4?
Assuming all users pretty much will use mirror/raid10/raidz1 for VMs, how come there isnt a sticky thread with some examples (yes I know those examples would have to be many - but at least with a few ones there will be something a user can have to make his own assumptions).
Thank you
PS I mean each diagram on net showing that type of raid level with letters like below
View attachment 37357
Ok I get that the greater the number of mirrors the greater the number of data-junks that needs to be spread across those disks (even though raid 10 claims this to be happening simultaneously)
I am trying to understand if 4k or 8k consists of A1 ->A8 parts. If yes still I dont get how you get that <<At minimum, you will need to use 8K => 4k for first mirror + 4k for the second mirror.>> At the end, I can t correlate the above diagram with kilobytes.



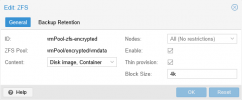
") You have a raid10(striped mirror), so any 4k VM block must be split on each mirror(4k). At minimum, you will need to use 8K => 4k for first mirror + 4k for the second mirror.
You have a raid10(striped mirror), so any 4k VM block must be split on each mirror(4k). At minimum, you will need to use 8K => 4k for first mirror + 4k for the second mirror.