Hello,
I've got a problem with spurious full PVE freezes where I can't even tell what is happening.
Setup: AMD EPYC 7702 KVM Host, in which my PVE is running (so it's PVE nested inside a KVM host with VMX flag).
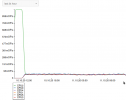
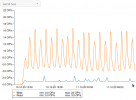
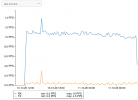
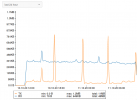
After some time (18 days / 30 days..) the full system is unresponsive and one Core is at 100% Usage, the rest is completely idle. No Network response etc
I attached some screenshots of the management console the Host has where you can see the CPU usage and 0 on everything else. One is from when it happened, the others are from right now, where you can see the normal usage vs the beginning while PVE was hanging.
I've got no logs or anything when this happens. When I reset the system everything goes back to normal.
I don't even have a clue where I can start debugging this. I've got one live OS-Snapshost, so maybe I can debug this or provide additional details if you have any ideas how.
I've got a problem with spurious full PVE freezes where I can't even tell what is happening.
Setup: AMD EPYC 7702 KVM Host, in which my PVE is running (so it's PVE nested inside a KVM host with VMX flag).
After some time (18 days / 30 days..) the full system is unresponsive and one Core is at 100% Usage, the rest is completely idle. No Network response etc
I attached some screenshots of the management console the Host has where you can see the CPU usage and 0 on everything else. One is from when it happened, the others are from right now, where you can see the normal usage vs the beginning while PVE was hanging.
I've got no logs or anything when this happens. When I reset the system everything goes back to normal.
I don't even have a clue where I can start debugging this. I've got one live OS-Snapshost, so maybe I can debug this or provide additional details if you have any ideas how.
Attachments

Last edited:

")
