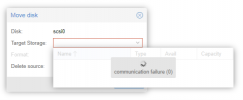
systemctl status pvestatd.service pvedaemon.service pveproxy.service
● pvestatd.service - PVE Status Daemon
Loaded: loaded (/lib/systemd/system/pvestatd.service; enabled; vendor preset: enabled)
Active: active (running) since Sat 2021-03-06 13:51:23 CET; 1 months 0 days ago
Process: 3442 ExecStart=/usr/bin/pvestatd start (code=exited, status=0/SUCCESS)
Process: 202305 ExecReload=/usr/bin/pvestatd restart (code=exited, status=0/SUCCESS)
Main PID: 3462 (pvestatd)
Tasks: 2 (limit: 39321)
Memory: 723.3M
CGroup: /system.slice/pvestatd.service
├─ 3462 pvestatd
└─110097 /sbin/lvs --separator : --noheadings --units b --unbuffered --nosuffix --config report/time_format="%s" --options vg_name,lv_name,lv_size,lv_attr,pool_lv,data_percent,metadata_percent,snap_p
Apr 06 09:56:51 pve02 pvestatd[3462]: status update time (73.038 seconds)
Apr 06 09:57:55 pve02 pvestatd[3462]: status update time (64.463 seconds)
Apr 06 09:59:03 pve02 pvestatd[3462]: status update time (68.125 seconds)
Apr 06 10:00:12 pve02 pvestatd[3462]: status update time (68.682 seconds)
Apr 06 10:01:17 pve02 pvestatd[3462]: status update time (64.721 seconds)
Apr 06 10:02:25 pve02 pvestatd[3462]: status update time (68.150 seconds)
Apr 06 10:03:30 pve02 pvestatd[3462]: status update time (65.020 seconds)
Apr 06 10:04:34 pve02 pvestatd[3462]: status update time (64.463 seconds)
Apr 06 10:05:39 pve02 pvestatd[3462]: status update time (64.497 seconds)
Apr 06 10:06:47 pve02 pvestatd[3462]: status update time (68.116 seconds)
● pvedaemon.service - PVE API Daemon
Loaded: loaded (/lib/systemd/system/pvedaemon.service; enabled; vendor preset: enabled)
Active: active (running) since Sat 2021-03-06 13:51:24 CET; 1 months 0 days ago
Process: 3460 ExecStart=/usr/bin/pvedaemon start (code=exited, status=0/SUCCESS)
Main PID: 3487 (pvedaemon)
Tasks: 4 (limit: 39321)
Memory: 199.7M
CGroup: /system.slice/pvedaemon.service
├─ 3487 pvedaemon
├─ 60946 pvedaemon worker
├─ 87355 pvedaemon worker
└─117399 pvedaemon worker
Apr 06 08:20:55 pve02 pvedaemon[3487]: starting 1 worker(s)
Apr 06 08:20:55 pve02 pvedaemon[3487]: worker 200864 started
Apr 06 08:55:52 pve02 pvedaemon[137775]: worker exit
Apr 06 08:55:52 pve02 pvedaemon[3487]: worker 137775 finished
Apr 06 08:55:52 pve02 pvedaemon[3487]: starting 1 worker(s)
Apr 06 08:55:52 pve02 pvedaemon[3487]: worker 60946 started
Apr 06 09:10:40 pve02 pvedaemon[200864]: worker exit
Apr 06 09:10:40 pve02 pvedaemon[3487]: worker 200864 finished
Apr 06 09:10:40 pve02 pvedaemon[3487]: starting 1 worker(s)
Apr 06 09:10:40 pve02 pvedaemon[3487]: worker 117399 started
● pveproxy.service - PVE API Proxy Server
Loaded: loaded (/lib/systemd/system/pveproxy.service; enabled; vendor preset: enabled)
Active: active (running) since Sat 2021-03-06 13:51:25 CET; 1 months 0 days ago
Process: 3492 ExecStartPre=/usr/bin/pvecm updatecerts --silent (code=exited, status=1/FAILURE)
Process: 3494 ExecStart=/usr/bin/pveproxy start (code=exited, status=0/SUCCESS)
Process: 6256 ExecReload=/usr/bin/pveproxy restart (code=exited, status=0/SUCCESS)
Main PID: 3636 (pveproxy)
Tasks: 4 (limit: 39321)
Memory: 190.2M
CGroup: /system.slice/pveproxy.service
├─ 3636 pveproxy
├─ 6545 pveproxy worker
├─16143 pveproxy worker
└─38019 pveproxy worker
Apr 06 08:39:57 pve02 pveproxy[3636]: starting 1 worker(s)
Apr 06 08:39:57 pve02 pveproxy[3636]: worker 6545 started
Apr 06 08:42:49 pve02 pveproxy[6339]: worker exit
Apr 06 08:42:49 pve02 pveproxy[3636]: worker 6339 finished
Apr 06 08:42:49 pve02 pveproxy[3636]: starting 1 worker(s)
Apr 06 08:42:49 pve02 pveproxy[3636]: worker 16143 started
Apr 06 08:48:57 pve02 pveproxy[6337]: worker exit
Apr 06 08:48:57 pve02 pveproxy[3636]: worker 6337 finished
Apr 06 08:48:57 pve02 pveproxy[3636]: starting 1 worker(s)
Apr 06 08:48:57 pve02 pveproxy[3636]: worker 38019 started