Latest activity
-
 UdoB reacted to LnxBil's post in the thread Beratung / Best Practise: ein PBS mit Storages per CIFS oder drei PBS mit gegenseitigen Remotes? with
UdoB reacted to LnxBil's post in the thread Beratung / Best Practise: ein PBS mit Storages per CIFS oder drei PBS mit gegenseitigen Remotes? with Like.
Eher weniger, hier spielt das lokale Storage auf dem PBS eine entscheidende Rolle: wenn du kein Full-Flash-System hast, wird das das Problem sein. Eine akzeptable Performance erreicht man mit lokalen ZFS auf Festplatten, wenn man special devices...
Like.
Eher weniger, hier spielt das lokale Storage auf dem PBS eine entscheidende Rolle: wenn du kein Full-Flash-System hast, wird das das Problem sein. Eine akzeptable Performance erreicht man mit lokalen ZFS auf Festplatten, wenn man special devices... -
Thank you for confirming. Both disks will be 2TB. I take it that sgdisk --zap-all /dev/sdX will be sufficient for clearing all disk structures before attaching it to the zfs pool? I will read the man page to get a better understanding of the...
-
 LnxBil replied to the thread Beratung / Best Practise: ein PBS mit Storages per CIFS oder drei PBS mit gegenseitigen Remotes?.... und Veeam weiter zu verwenden ist keine Option?
LnxBil replied to the thread Beratung / Best Practise: ein PBS mit Storages per CIFS oder drei PBS mit gegenseitigen Remotes?.... und Veeam weiter zu verwenden ist keine Option? -
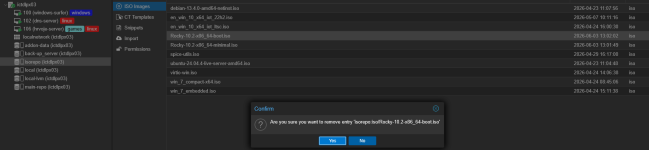
 dcsapak replied to the thread Remove attached ISO.i guess it's not checked because such a check will always be incomplete. to check every vm we'd have to iterate over all vm configs on all nodes, but while the check is running nobody is prevented to add the iso to a vm again. alternatively the...
dcsapak replied to the thread Remove attached ISO.i guess it's not checked because such a check will always be incomplete. to check every vm we'd have to iterate over all vm configs on all nodes, but while the check is running nobody is prevented to add the iso to a vm again. alternatively the... -
Jj.theisen replied to the thread Beratung / Best Practise: ein PBS mit Storages per CIFS oder drei PBS mit gegenseitigen Remotes?.Hi @philippms vielen Dank für deinen Post! SMB / CIFS ist im Vergleich ein relativ redseliges Protokoll und mag daher Latenzen nicht besonders. Da der Proxmox Backup Server für seinen Sync zwischen Remotes HTTP(S) verwendet, welches besser mit...
-
KKevinK replied to the thread Opt-in Linux 7.0 Kernel for Proxmox VE 9 available.Hit a hard regression on 7.0.12-1-pve on a Ryzen 9 5950X box - after a routine reboot, no VM or container would start. `qm start` returned without error but guests stayed `stopped`, and load sat at ~8 with nothing actually running. Root cause is...
-
Pphilippms replied to the thread Beratung / Best Practise: ein PBS mit Storages per CIFS oder drei PBS mit gegenseitigen Remotes?.Absolut. Steht außer Frage. Ich frage mich nur: Lohnt der Aufwand, drei PBS Systeme zu betreiben, die als Remote kommunizieren oder bringt das nicht den großen Vorteil gegenüber der CIFS-Lösung? Die CIFS-Lösung hat unter Veeam jahrelang gut...
-
DDrNoname replied to the thread Windows 2025 Freeze seit PVE 9.2.2.Habe es jetzt ausprobiert, wie Du es vorgeschlagen hast: cpu: "host", nested-virt "aus" -> funktioniert -> vielen Dank!
-
AHi, I have a 3 nodes in proxmox cluster on each node I have clustered storage, i use it for ISO images. this storage mount as local # cat /etc/pve/storage.cfg dir: isorepo path /mnt/ocfs content vztmpl,import,iso,snippets,rootdir...
-
-
Mmvdhoeven posted the thread [SOLVED] WSL2 issue on Windows 2025 VM - PVE with Kernel 7.0 + QEMU 11 (works with QEMU 10) in Proxmox VE: Installation and configuration.Hi all, I’m running into an issue with WSL2 inside a Windows Server 2025 VM after upgrading to Linux Kernel 7.0 and QEMU 11, and I’m hoping someone else has seen this or can point me in the right direction. Environment Proxmox cluster with 2...
-
Ddaveanderson replied to the thread Broadcom BCM57504 (100G) bnxt_en TX timeout and NIC reset on Proxmox 8.1.5 — while BCM57414 (25G) works fine on same host.looks like kernel 7.0.13 has some bnxt_en fixes, though unclear if any of them are actually relevant to the crashes we're seeing. https://www.kernel.org/pub/linux/kernel/v7.x/ChangeLog-7.0.13 guessing it'll be awhile before those changes get...
-
LnxBil replied to the thread Making linked clones from snapshots of VMs (NOT TEMPLATES).If you do that yes, if you don't it won't. You have to do it manually with zfs clone and that is just a reference clone, but you need to do this yourself, e.g. with ansible or any other tooling of your choice: create a VM, this will create it...
-
 fiona replied to the thread Proxmox Virtual Environment 9.2 available!.Hi, please provide the VM configuration qm config ID with the numerical ID of an affected VM as well as the output of pveversion -v. Can you see anything in the host system logs/journal? What kind of guest OS and kernel does the VM use?
fiona replied to the thread Proxmox Virtual Environment 9.2 available!.Hi, please provide the VM configuration qm config ID with the numerical ID of an affected VM as well as the output of pveversion -v. Can you see anything in the host system logs/journal? What kind of guest OS and kernel does the VM use? -
Ffabian69420 replied to the thread [SOLVED] Can't get Nvidia GPU passthrough to work on LXC.# pct start 103 --debug run_buffer: 569 Script exited with status 255 lxc_init: 1037 Failed to run lxc.hook.pre-start for container "103" __lxc_start: 2208 Failed to initialize container "103" hostid 100000 range 65536 INFO lsm -...
-
No crash here for nearly 6 days with 6.8.12-30-pve. Thanks a lot for the fix. Has 6.8.12-29-pve been published in the enterprise repos as well?
-
fiona replied to the thread Updated to 8.2 - DMA error.No, as of now, the newest version in the enterprise repository is still 6.8.12-28-pve and the broken version will only be imported to the enterprise repository at the same time as the fixed version.
-
Ppato_ehm reacted to LnxBil's post in the thread Making linked clones from snapshots of VMs (NOT TEMPLATES) with Like.
AFAIK, this is a (hopefully) temporary limitation that has been worked on in the past and it only concerns the EFI disk. You can always create a cloned VM manually yourself, if you build a new VM, clone the data disk and create a new EFI disk...
-
CClaudio.Sachespi replied to the thread Replication in Proxmox.You could use a third Witnees machine to orchestrate the replicas. Try it as a VM on one of the nodes, but then plan to move it outside. It also runs on a Raspberry.
-
 driley replied to the thread Win Server 2025 VM: DPC_WATCHDOG_VIOLATION 0x133 after upgrade to Kernel 7.x.Hi @brnogu, The kernel update addressing this specific issue has already been released. It is available on the no-subscription repo as version 7.0.12-1-pve.
driley replied to the thread Win Server 2025 VM: DPC_WATCHDOG_VIOLATION 0x133 after upgrade to Kernel 7.x.Hi @brnogu, The kernel update addressing this specific issue has already been released. It is available on the no-subscription repo as version 7.0.12-1-pve. -
Ppato_ehm replied to the thread Making linked clones from snapshots of VMs (NOT TEMPLATES).Well yes, but this would be making a full clone right? My understanding was that Ceph must have at least 3 Nodes. It would be then possible to achieve this with one server only? We would have only one server with mutpile storages that we planned...