Latest activity
-
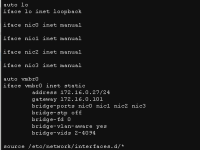
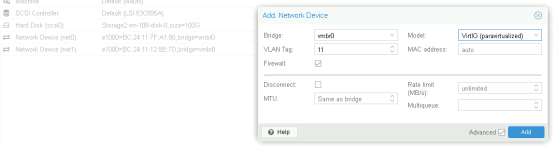
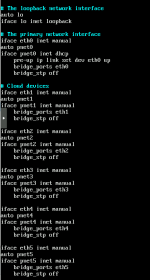
Jjacca92 posted the thread PNET VM inside Proxmox keeps looping in Proxmox VE: Networking and Firewall.Hello, I have a problem which I hope I will be able to describe. It's quite complex in my opinion, or I make it too complex for myself. Hard to say. Also, I am not entirely sure whether this is a correct place to post it. If not, take my post...
-
-
Ppiotrpierzchala replied to the thread Space reclamation on thin provisioning after removing file from debian 13 with qcow2 disk.Well... if you still have some spare time, just try to power OFF VM, migrate all disks on NFS 4.2 datastore, power it back ON. Create a file, delete it, run 'fstrim -av' and check qemu-img info. Space reclamation works every time without...
-
 VictorSTS reacted to Onslow's post in the thread [SOLVED] No zfstools in the latest kernel 6.17.9-1-pve with
VictorSTS reacted to Onslow's post in the thread [SOLVED] No zfstools in the latest kernel 6.17.9-1-pve with Like.
At https://packages.debian.org/forky/amd64/zfsutils-linux/filelist I can see there are /usr/bin/zarcstat and /usr/bin/zarcsummary Maybe those were renamed in the newer version? What about man zarcstat ? P.S. Indeed...
Like.
At https://packages.debian.org/forky/amd64/zfsutils-linux/filelist I can see there are /usr/bin/zarcstat and /usr/bin/zarcsummary Maybe those were renamed in the newer version? What about man zarcstat ? P.S. Indeed... -
Aaragel replied to the thread Cluster aware FS for shared datastores?.Proxmox plugin for SaunaFS is in the works and hope it won't take long to appear.
-
AHi! I'm looking for something similar for the new small setup: - "3-node-storage" with separate "3-node-hypervisor" ( 6 servers in total ). My searching found the followings for storage-nodes replication/HA: - MooseFS - https://moosefs.com -...
-
JOoh, consumer crucial, not good, not good.
-
JJohannes S reacted to Bu66as's post in the thread merkwürtiges Netzwerkproblem beim Zugriff auf PVE with Like.
@garfield2008 , Gut, damit ist die Ursache bestätigt. Was sich geändert hat: Vermutlich haben bei der Neuinstallation/dem Update die OVS-Bridges oder Bonds die MTU 9000 von den NICs übernommen (OVS negotiiert die MTU automatisch anhand der...
-
Jjotha replied to the thread [SOLVED] PVE 9.1.5: Linux VM Freeze Randomly.Hello Daniel, thanks for your reply! Yes, the IPfire has also a lot of logs (most are "firewall" related, but also kernel and other logs are included) and I checked it already, but I can't find any hint about the reason of failure. Currently...
-
-
Llethargos reacted to EdoFede's post in the thread Yet another "ZFS on HW-RAID" Thread (with benchmarks) with Like.
Congratulations, great behavior for a technical discussion forum! :) You simply didn't even read what I wrote in the entire thread, not even the very clear bolded parts. If you are not able to deal with a technical dialogue by discussing topics...
-
 gurubert reacted to Johannes S's post in the thread Pardon my less-than-intelligent question, but is there a way to install Proxmox on a Ceph cluster? with Like.
Although they were about replicated pools (so no ec) following reads might serve as a hint why (outside of experiments/lab setups) it's not a good idea to go against the recommendations...
gurubert reacted to Johannes S's post in the thread Pardon my less-than-intelligent question, but is there a way to install Proxmox on a Ceph cluster? with Like.
Although they were about replicated pools (so no ec) following reads might serve as a hint why (outside of experiments/lab setups) it's not a good idea to go against the recommendations... -
 fireon replied to the thread Proxmox 6 mpt3sas Debian Bug ICO Report 926202 with Loaded Controller.I also have the same error here under kernel 6.17. But the strange thing is that it does not happen under ZFS. I also tested other file systems: Ext4, LVM, XFS, BTRFS. The controller crashes with all of them. If you are not using ZFS, the only...
fireon replied to the thread Proxmox 6 mpt3sas Debian Bug ICO Report 926202 with Loaded Controller.I also have the same error here under kernel 6.17. But the strange thing is that it does not happen under ZFS. I also tested other file systems: Ext4, LVM, XFS, BTRFS. The controller crashes with all of them. If you are not using ZFS, the only... -
JJohannes S replied to the thread Pardon my less-than-intelligent question, but is there a way to install Proxmox on a Ceph cluster?.Although they were about replicated pools (so no ec) following reads might serve as a hint why (outside of experiments/lab setups) it's not a good idea to go against the recommendations...
-
JJohannes S reacted to gurubert's post in the thread Pardon my less-than-intelligent question, but is there a way to install Proxmox on a Ceph cluster? with Like.
With size=min_size you cannot lose any OSDs without losing write access to the affected objects. And it has nothing to do with number of nodes or number of OSDs.
-
JJohannes S reacted to gurubert's post in the thread Pardon my less-than-intelligent question, but is there a way to install Proxmox on a Ceph cluster? with Like.
This is not recommended and certainly not HA. With m=1 you cannot loose a single disk. An erasure coded pool should have size=k+m and min_size=k+1 settings which would be size=3 and min_size=3 in your case.
-
JJohannes S reacted to gurubert's post in the thread Pardon my less-than-intelligent question, but is there a way to install Proxmox on a Ceph cluster? with Like.
No no no. You got your math wrong. To achieve the same availability as EC with k=6 and m=2 you need triple replication (three copies) meaning a storage efficiency of 33%. It is rarely necessary to go beyond 4 copies.
-
BAlles klar, ich warte ab. Kann dauern ;-) danke
-
gurubert replied to the thread Pardon my less-than-intelligent question, but is there a way to install Proxmox on a Ceph cluster?.With size=min_size you cannot lose any OSDs without losing write access to the affected objects. And it has nothing to do with number of nodes or number of OSDs.
-
Aalpha754293 replied to the thread Pardon my less-than-intelligent question, but is there a way to install Proxmox on a Ceph cluster?.But I've got that with my three nodes, no? k = 2 m = 1 size=2+1 = 3 (which is what I have) min_size = k + 1 = 2 + 1 = 3 (which I have three nodes). So, I am struggling a little bit, in trying to understanding how size = min_size = 3 in my...
-
gurubert replied to the thread Pardon my less-than-intelligent question, but is there a way to install Proxmox on a Ceph cluster?.Yes. In erasure coded pools with m=2 you can lose 2 OSDs for one PG at the same time without losing data. The same can be achieved in replicated pools with size=3. You can lose 2 OSDs for a PG without losing its data.
-
Aalpha754293 replied to the thread Pardon my less-than-intelligent question, but is there a way to install Proxmox on a Ceph cluster?.Can you show me your math so that I can learn from it? Is the need for triple replication because it's m=2? I would like to learn how to arrived at this conclusion if you can expand a little further on how you are doing the math that leads you...