Latest activity
-
 UdoB reacted to SteveITS's post in the thread if reboot is triggered pve node goes away too fast before ha migration is finished with
UdoB reacted to SteveITS's post in the thread if reboot is triggered pve node goes away too fast before ha migration is finished with Like.
Another way to migrate all VMs (and have them migrate back to the same server) is to enable maintenance mode. On any server run: ha-manager crm-command node-maintenance enable pve1 (wait for migration, then reboot) ha-manager crm-command...
Like.
Another way to migrate all VMs (and have them migrate back to the same server) is to enable maintenance mode. On any server run: ha-manager crm-command node-maintenance enable pve1 (wait for migration, then reboot) ha-manager crm-command... -
Ffdcastel replied to the thread Proxmox x Hyper-V storage performance..Thanks, @ucholak! I wasn't aware of this command. It appears it's not: # nvme list Node Generic SN Model Namespace Usage Format...
-
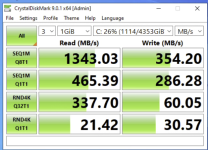
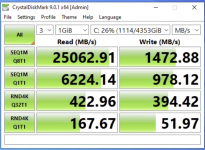
CCiber replied to the thread Ceph librbd vs krbd.Switched to KRBD and the difference is massive lol. Here's the before and after, writeback cache was enabled for both runs.
-
-
 shanreich replied to the thread VLAN and SDN struggles.Are you sure everything is set up properly on OpenWRT? If you see a TCP RST for some connections on the router (but not on the PVE host), then this might be an indicator that a firewall rejects packets. If you see nothing via tcpdump on the PVE...
shanreich replied to the thread VLAN and SDN struggles.Are you sure everything is set up properly on OpenWRT? If you see a TCP RST for some connections on the router (but not on the PVE host), then this might be an indicator that a firewall rejects packets. If you see nothing via tcpdump on the PVE... -
 fiona replied to the thread QEMU VM startup timeout.Currently, it's only possible when starting via CLI. The feature request I referenced is still open, i.e. not yet implemented.
fiona replied to the thread QEMU VM startup timeout.Currently, it's only possible when starting via CLI. The feature request I referenced is still open, i.e. not yet implemented. -
SSteveITS replied to the thread if reboot is triggered pve node goes away too fast before ha migration is finished.Another way to migrate all VMs (and have them migrate back to the same server) is to enable maintenance mode. On any server run: ha-manager crm-command node-maintenance enable pve1 (wait for migration, then reboot) ha-manager crm-command...
-
Ffdcastel replied to the thread Proxmox x Hyper-V storage performance..I didn't even try. According to Proxmox VE documentation: The VirtIO Block controller, often just called VirtIO or virtio-blk, is an older type of paravirtualized controller. It has been superseded by the VirtIO SCSI Controller, in terms of...
-
fiona replied to the thread Migrating with Conntrack doesn't work after Updating to 9.0.5.Hi @woma , your issue sounds a bit different. HA does not currently migrate with conntrack state. The error message you get is the same as in the following bug report: https://bugzilla.proxmox.com/show_bug.cgi?id=7092 There, the migration still...
-
 CarstenMartens replied to the thread ACME Plugin - Hetzner "DNS Console is moving to the Hetzner Console".That wasn't the intention – my English isn't as good as it should be after nine years of school – but it's simply time-consuming when multiple systems have to be manually updated instead of using patches. And if we switch the Hetzner DNS, we'll...
CarstenMartens replied to the thread ACME Plugin - Hetzner "DNS Console is moving to the Hetzner Console".That wasn't the intention – my English isn't as good as it should be after nine years of school – but it's simply time-consuming when multiple systems have to be manually updated instead of using patches. And if we switch the Hetzner DNS, we'll... -
 bbgeek17 replied to the thread migration plan from vsan cluster to proxmox.Looking at the man page of the QM: qm import <vmid> <source> --storage <string> [OPTIONS] Import a foreign virtual guest from a supported import source, such as an ESXi storage. <vmid>: <integer> (100 - 999999999) The...
bbgeek17 replied to the thread migration plan from vsan cluster to proxmox.Looking at the man page of the QM: qm import <vmid> <source> --storage <string> [OPTIONS] Import a foreign virtual guest from a supported import source, such as an ESXi storage. <vmid>: <integer> (100 - 999999999) The... -
Jjrl_1644 replied to the thread Anybody running PBS on UGreen units?.Another update. My issue turned out to be Orico J-10 NVME drives. Not a single hang in months since replacing the drives. Although the microcode update did help,.
-
DDer Harry replied to the thread ACME Plugin - Hetzner "DNS Console is moving to the Hetzner Console".No blaming. Also being a developer - their #1 Priority (that what makes money) was on the Proxmox Datacenter Manager. I just kindly asked asked about the plans to update acme.sh in the bugzilla ticket. At some time I just post a bash script here...
-
fiona replied to the thread KRBD 0 Ceph prevents VMs from starting.[pid 1373949] openat(AT_FDCWD, "/etc/ceph/ceph-metal.client.admin.keyring", O_RDONLY|O_CLOEXEC) = -1 ENOENT (No such file or directory) [pid 1373949] openat(AT_FDCWD, "/etc/ceph/ceph-metal.keyring", O_RDONLY|O_CLOEXEC) = -1 ENOENT (No such file...
-
Naja, NFS ist so simpel, dass es praktisch ein offenes Scheunentor ist, Goldstandard würde ich das nicht nennen: https://talks.mrmcd.net/2024/talk/7RR38D/ Außer man konfiguriert Kerberos, aber dann ist es nicht mehr simpel. Nicht falsch...
-
CarstenMartens replied to the thread ACME Plugin - Hetzner "DNS Console is moving to the Hetzner Console".Hello, Yes, I saw that no update was installed for it yesterday. That's a real shame. I manually configured it on our test system for testing purposes, and it worked. However, I don't want to do that manually on the other 13 systems.
-
Wwoma replied to the thread Migrating with Conntrack doesn't work after Updating to 9.0.5.I updated my small no-subscription PVE cluster today to latest V9 packages. I used "shutdown policy=migragte" and triggered a shutdown for node2 (Dec 16 12:40:30) Expectation was that started HA VM 102 will be "online" migrated from node2 to...
-
CarstenMartens reacted to Der Harry's post in the thread ACME Plugin - Hetzner "DNS Console is moving to the Hetzner Console" with Like.
I post the git repo here: https://git.proxmox.com/?p=proxmox-acme.git;a=summary Unfortunately yesterdays commit didn't have an update. I still have a few weeks on my server but at some point I might post a script here to patch the files.
-
DDer Harry replied to the thread ACME Plugin - Hetzner "DNS Console is moving to the Hetzner Console".I post the git repo here: https://git.proxmox.com/?p=proxmox-acme.git;a=summary Unfortunately yesterdays commit didn't have an update. I still have a few weeks on my server but at some point I might post a script here to patch the files.
-
Pptselios replied to the thread VLAN and SDN struggles.And the ip commands: 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever...
-
Pptselios replied to the thread VLAN and SDN struggles.In the meantime, I removed zone LXC since it was not working at all: cat /etc/network/interfaces.d/sdn #version:19 auto BMCnet iface BMCnet bridge_ports ln_BMCnet bridge_stp off bridge_fd 0 alias BMC Network auto External iface External...