Hello everyone,
I’m running Proxmox 8.3.3, and after a brief power outage (just a few minutes) which caused my system to shut down abruptly, I’ve encountered an issue where the status of all my VMs and LXC containers is now showing as "Unknown." I also can't find the configuration files for the containers or VMs anywhere.
Here’s a quick summary of what I’ve observed:
Has anyone experienced something similar? Any advice on how I can recover my VMs and containers or locate the missing config files would be greatly appreciated.
Thanks in advance for any help!
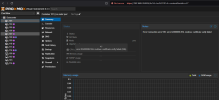
Health status
no output while listing vms and lxc containers:
root@proxmox01:~# qm list
root@proxmox01:~# pct list
but
I’m running Proxmox 8.3.3, and after a brief power outage (just a few minutes) which caused my system to shut down abruptly, I’ve encountered an issue where the status of all my VMs and LXC containers is now showing as "Unknown." I also can't find the configuration files for the containers or VMs anywhere.
Here’s a quick summary of what I’ve observed:
- All VMs and containers show up with the status "Unknown" in the Proxmox GUI.
- I can’t start any of the VMs or containers.
- The configuration files for the VMs and containers appear to be missing.
- The system itself seems to be running fine otherwise, but the VM and container management seems completely broken.
Has anyone experienced something similar? Any advice on how I can recover my VMs and containers or locate the missing config files would be greatly appreciated.
Thanks in advance for any help!
Health status
root@proxmox01:~# df -h
Filesystem Size Used Avail Use% Mounted on
udev 16G 0 16G 0% /dev
tmpfs 3.1G 1.3M 3.1G 1% /run
/dev/mapper/pve-root 102G 47G 51G 48% /
tmpfs 16G 34M 16G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
efivarfs 128K 37K 87K 30% /sys/firmware/efi/efivars
/dev/nvme1n1p1 916G 173G 697G 20% /mnt/storage
/dev/sda2 511M 336K 511M 1% /boot/efi
/dev/fuse 128M 32K 128M 1% /etc/pve
tmpfs 3.1G 0 3.1G 0% /run/user/0
root@proxmox01:~# df -h
Filesystem Size Used Avail Use% Mounted on
udev 16G 0 16G 0% /dev
tmpfs 3.1G 1.4M 3.1G 1% /run
/dev/mapper/pve-root 102G 47G 51G 48% /
tmpfs 16G 34M 16G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
efivarfs 128K 37K 87K 30% /sys/firmware/efi/efivars
/dev/nvme1n1p1 916G 173G 697G 20% /mnt/storage
/dev/sda2 511M 336K 511M 1% /boot/efi
/dev/fuse 128M 32K 128M 1% /etc/pve
tmpfs 3.1G 0 3.1G 0% /run/user/0
root@proxmox01:~# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sda 8:0 0 111.8G 0 disk
├─sda1 8:1 0 1007K 0 part
├─sda2 8:2 0 512M 0 part /boot/efi
└─sda3 8:3 0 111.3G 0 part
├─pve-swap 252:0 0 8G 0 lvm [SWAP]
└─pve-root 252:1 0 103.3G 0 lvm /
sdb 8:16 0 3.6T 0 disk
└─sdb1 8:17 0 3.6T 0 part
sdc 8:32 0 7.3T 0 disk
└─sdc1 8:33 0 7.3T 0 part
sdd 8:48 0 7.3T 0 disk
└─sdd1 8:49 0 7.3T 0 part
sde 8:64 0 3.6T 0 disk
└─sde1 8:65 0 3.6T 0 part
nvme1n1 259:0 0 931.5G 0 disk
└─nvme1n1p1 259:3 0 931.5G 0 part /mnt/storage
nvme0n1 259:1 0 1.8T 0 disk
└─nvme0n1p1 259:2 0 1.8T 0 part
no output while listing vms and lxc containers:
root@proxmox01:~# qm list
root@proxmox01:~# pct list
but
root@proxmox01:~# lxc-ls --fancy
NAME STATE AUTOSTART GROUPS IPV4 IPV6 UNPRIVILEGED
101 STOPPED 0 - - - true
104 STOPPED 0 - - - true
105 STOPPED 0 - - - false
106 STOPPED 0 - - - true
107 STOPPED 0 - - - false
108 STOPPED 0 - - - true
109 STOPPED 0 - - - true
110 STOPPED 0 - - - false
111 STOPPED 0 - - - true
114 STOPPED 0 - - - true
root@proxmox01:~# pveversion -v
proxmox-ve: 8.3.0 (running kernel: 6.8.12-7-pve)
pve-manager: 8.3.3 (running version: 8.3.3/f157a38b211595d6)
proxmox-kernel-helper: 8.1.0
pve-kernel-5.15: 7.4-15
proxmox-kernel-6.8: 6.8.12-7
proxmox-kernel-6.8.12-7-pve-signed: 6.8.12-7
proxmox-kernel-6.8.12-2-pve-signed: 6.8.12-2
pve-kernel-5.15.158-2-pve: 5.15.158-2
pve-kernel-5.15.74-1-pve: 5.15.74-1
ceph-fuse: 16.2.15+ds-0+deb12u1
corosync: 3.1.7-pve3
criu: 3.17.1-2+deb12u1
glusterfs-client: 10.3-5
ifupdown2: 3.2.0-1+pmx11
ksm-control-daemon: 1.5-1
libjs-extjs: 7.0.0-5
libknet1: 1.28-pve1
libproxmox-acme-perl: 1.5.1
libproxmox-backup-qemu0: 1.4.1
libproxmox-rs-perl: 0.3.4
libpve-access-control: 8.2.0
libpve-apiclient-perl: 3.3.2
libpve-cluster-api-perl: 8.0.10
libpve-cluster-perl: 8.0.10
libpve-common-perl: 8.2.9
libpve-guest-common-perl: 5.1.6
libpve-http-server-perl: 5.1.2
libpve-network-perl: 0.10.0
libpve-rs-perl: 0.9.1
libpve-storage-perl: 8.3.3
libspice-server1: 0.15.1-1
lvm2: 2.03.16-2
lxc-pve: 6.0.0-1
lxcfs: 6.0.0-pve2
novnc-pve: 1.5.0-1
proxmox-backup-client: 3.3.2-1
proxmox-backup-file-restore: 3.3.2-2
proxmox-firewall: 0.6.0
proxmox-kernel-helper: 8.1.0
proxmox-mail-forward: 0.3.1
proxmox-mini-journalreader: 1.4.0
proxmox-widget-toolkit: 4.3.4
pve-cluster: 8.0.10
pve-container: 5.2.3
pve-docs: 8.3.1
pve-edk2-firmware: 4.2023.08-4
pve-esxi-import-tools: 0.7.2
pve-firewall: 5.1.0
pve-firmware: 3.14-3
pve-ha-manager: 4.0.6
pve-i18n: 3.3.3
pve-qemu-kvm: 9.0.2-5
pve-xtermjs: 5.3.0-3
qemu-server: 8.3.6
smartmontools: 7.3-pve1
spiceterm: 3.3.0
swtpm: 0.8.0+pve1
vncterm: 1.8.0
zfsutils-linux: 2.2.7-pve1