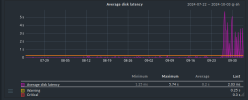
We have strange disk latency spikes after rebooting Ubuntu 22.04 guest with kernel 6.8. On screenshots of our monitoring system graphs you can see that disk latency is 3-5 second, but disk load is minimal ( see second screenshot disk throughput/operations).
Proxmox version is 8.3:
proxmox-ve: 8.3.0 (running kernel: 6.5.13-1-pve)
pve-manager: 8.3.2 (running version: 8.3.2/3e76eec21c4a14a7)
proxmox-kernel-helper: 8.1.0
proxmox-kernel-6.8: 6.8.12-4
proxmox-kernel-6.8.12-4-pve-signed: 6.8.12-4
proxmox-kernel-6.8.12-2-pve-signed: 6.8.12-2
proxmox-kernel-6.5.13-6-pve-signed: 6.5.13-6
proxmox-kernel-6.5: 6.5.13-6
proxmox-kernel-6.5.13-1-pve-signed: 6.5.13-1
ceph: 18.2.4-pve3
ceph-fuse: 18.2.4-pve3
corosync: 3.1.7-pve3
criu: 3.17.1-2+deb12u1
glusterfs-client: 10.3-5
ifupdown: residual config
ifupdown2: 3.2.0-1+pmx11
intel-microcode: 3.20241112.1~deb12u1
ksm-control-daemon: 1.4-1
libjs-extjs: 7.0.0-5
libknet1: 1.28-pve1
libproxmox-acme-perl: 1.5.1
libproxmox-backup-qemu0: 1.4.1
libproxmox-rs-perl: 0.3.4
libpve-access-control: 8.2.0
libpve-apiclient-perl: 3.3.2
libpve-cluster-api-perl: 8.0.10
libpve-cluster-perl: 8.0.10
libpve-common-perl: 8.2.9
libpve-guest-common-perl: 5.1.6
libpve-http-server-perl: 5.1.2
libpve-network-perl: 0.10.0
libpve-rs-perl: 0.9.1
libpve-storage-perl: 8.3.2
libqb0: 1.0.5-1
libspice-server1: 0.15.1-1
lvm2: 2.03.16-2
lxc-pve: 6.0.0-1
lxcfs: 6.0.0-pve2
novnc-pve: 1.5.0-1
proxmox-backup-client: 3.3.2-1
proxmox-backup-file-restore: 3.3.2-2
proxmox-firewall: 0.6.0
proxmox-kernel-helper: 8.1.0
proxmox-mail-forward: 0.3.1
proxmox-mini-journalreader: 1.4.0
proxmox-offline-mirror-helper: 0.6.7
proxmox-widget-toolkit: 4.3.3
pve-cluster: 8.0.10
pve-container: 5.2.2
pve-docs: 8.3.1
pve-edk2-firmware: 4.2023.08-4
pve-esxi-import-tools: 0.7.2
pve-firewall: 5.1.0
pve-firmware: 3.14-1
pve-ha-manager: 4.0.6
pve-i18n: 3.3.2
pve-qemu-kvm: 9.0.2-4
pve-xtermjs: 5.3.0-3
qemu-server: 8.3.3
smartmontools: 7.3-pve1
spiceterm: 3.3.0
swtpm: 0.8.0+pve1
vncterm: 1.8.0
zfsutils-linux: 2.2.6-pve1
Storage is CEPH 18.2.4 build with 108 enterprise NVMe SSDs (Micron 9300 max). No consumer class or read optimized SSDs are used for CEPH OSDs.
We don't have any latency or slow requests warnings in CEPH.
VM configuration:
agent: 1
balloon: 3072
bootdisk: scsi0
cores: 12
cpu: x86-64-v2-AES
hotplug: disk,network,usb,memory,cpu
memory: 4096
name: my-vm.example.com
net0: virtio=BC:24:11:30:28:A3,bridge=vmbr0,firewall=1,queues=2
net1: virtio=BC:24:11:80:25:30,bridge=grnet,mtu=8950,queues=2
numa: 1
ostype: l26
sata0: none,media=cdrom
sata1: SSD:vm-204-cloudinit,media=cdrom,size=4M
scsi0: SSD:vm-204-disk-0,cache=writeback,discard=on,size=1G
scsi1: SSD:vm-204-disk-1,cache=writeback,discard=on,size=30G
scsihw: virtio-scsi-single
serial0: socket
sockets: 2
usb0: spice,usb3=1
vcpus: 2
vga: virtio
We tried many different confgiration options (different SCSI controllers, different cache ,modes, No cache, direct sync, with or without iothreads, asinc io io_uting or native). Nothing helps. Guest disk latency only decreases whet we booot the VM with kernel 6.5 or 5.15.
Does anyone have a similar problem?
Proxmox version is 8.3:
proxmox-ve: 8.3.0 (running kernel: 6.5.13-1-pve)
pve-manager: 8.3.2 (running version: 8.3.2/3e76eec21c4a14a7)
proxmox-kernel-helper: 8.1.0
proxmox-kernel-6.8: 6.8.12-4
proxmox-kernel-6.8.12-4-pve-signed: 6.8.12-4
proxmox-kernel-6.8.12-2-pve-signed: 6.8.12-2
proxmox-kernel-6.5.13-6-pve-signed: 6.5.13-6
proxmox-kernel-6.5: 6.5.13-6
proxmox-kernel-6.5.13-1-pve-signed: 6.5.13-1
ceph: 18.2.4-pve3
ceph-fuse: 18.2.4-pve3
corosync: 3.1.7-pve3
criu: 3.17.1-2+deb12u1
glusterfs-client: 10.3-5
ifupdown: residual config
ifupdown2: 3.2.0-1+pmx11
intel-microcode: 3.20241112.1~deb12u1
ksm-control-daemon: 1.4-1
libjs-extjs: 7.0.0-5
libknet1: 1.28-pve1
libproxmox-acme-perl: 1.5.1
libproxmox-backup-qemu0: 1.4.1
libproxmox-rs-perl: 0.3.4
libpve-access-control: 8.2.0
libpve-apiclient-perl: 3.3.2
libpve-cluster-api-perl: 8.0.10
libpve-cluster-perl: 8.0.10
libpve-common-perl: 8.2.9
libpve-guest-common-perl: 5.1.6
libpve-http-server-perl: 5.1.2
libpve-network-perl: 0.10.0
libpve-rs-perl: 0.9.1
libpve-storage-perl: 8.3.2
libqb0: 1.0.5-1
libspice-server1: 0.15.1-1
lvm2: 2.03.16-2
lxc-pve: 6.0.0-1
lxcfs: 6.0.0-pve2
novnc-pve: 1.5.0-1
proxmox-backup-client: 3.3.2-1
proxmox-backup-file-restore: 3.3.2-2
proxmox-firewall: 0.6.0
proxmox-kernel-helper: 8.1.0
proxmox-mail-forward: 0.3.1
proxmox-mini-journalreader: 1.4.0
proxmox-offline-mirror-helper: 0.6.7
proxmox-widget-toolkit: 4.3.3
pve-cluster: 8.0.10
pve-container: 5.2.2
pve-docs: 8.3.1
pve-edk2-firmware: 4.2023.08-4
pve-esxi-import-tools: 0.7.2
pve-firewall: 5.1.0
pve-firmware: 3.14-1
pve-ha-manager: 4.0.6
pve-i18n: 3.3.2
pve-qemu-kvm: 9.0.2-4
pve-xtermjs: 5.3.0-3
qemu-server: 8.3.3
smartmontools: 7.3-pve1
spiceterm: 3.3.0
swtpm: 0.8.0+pve1
vncterm: 1.8.0
zfsutils-linux: 2.2.6-pve1
Storage is CEPH 18.2.4 build with 108 enterprise NVMe SSDs (Micron 9300 max). No consumer class or read optimized SSDs are used for CEPH OSDs.
We don't have any latency or slow requests warnings in CEPH.
VM configuration:
agent: 1
balloon: 3072
bootdisk: scsi0
cores: 12
cpu: x86-64-v2-AES
hotplug: disk,network,usb,memory,cpu
memory: 4096
name: my-vm.example.com
net0: virtio=BC:24:11:30:28:A3,bridge=vmbr0,firewall=1,queues=2
net1: virtio=BC:24:11:80:25:30,bridge=grnet,mtu=8950,queues=2
numa: 1
ostype: l26
sata0: none,media=cdrom
sata1: SSD:vm-204-cloudinit,media=cdrom,size=4M
scsi0: SSD:vm-204-disk-0,cache=writeback,discard=on,size=1G
scsi1: SSD:vm-204-disk-1,cache=writeback,discard=on,size=30G
scsihw: virtio-scsi-single
serial0: socket
sockets: 2
usb0: spice,usb3=1
vcpus: 2
vga: virtio
We tried many different confgiration options (different SCSI controllers, different cache ,modes, No cache, direct sync, with or without iothreads, asinc io io_uting or native). Nothing helps. Guest disk latency only decreases whet we booot the VM with kernel 6.5 or 5.15.
Does anyone have a similar problem?
Attachments

Last edited:

