Hallo zusammen,
Ich habe seit geraumer Zeit ein Problem, dass bei hohem IO delay teilweise wahllos VMs crashen bzw. ich vermute den IO delay dahinter.
Zu meinem Setup:
- 3 baugleiche Server (CPU: Intel Xeon E-2176G, RAM: 64GB ECC)
- 2 Server mit 2x1TB SSD
- 1 Server nur 2x4TB HDD
- PVE 6.2-4
- ZFS
zfs_arc_min und zfs_arc_max sind gesetzt:
options zfs zfs_arc_min=4294967296
options zfs zfs_arc_max=8589934592
Ich kann das ganze recht einfach reproduzieren.
Einfach ein großes zip oder rar entpacken und abwarten.
Manchmal crashed die VM die entpackt, manchmal aber auch wahllos eine andere auf dem gleichen Host.
Wenn ich nun hergehe und der virtuellen Hard Disk im PVE UI jeweils read und write limit verpasse (dieses muss dann aber sehr niedrig sein, beispielsweise 20 MB/s), dann läuft alles tip-top durch und keine der VMs crashed.
Hauptsächlich tritt das bei dem Host mit den HDDs auf, ich habe es aber auch geschafft, es bei den SSDs nachzustellen, hier muss die Last auf die Platten aber ungleich größer sein. Daher kam ich auch zu der Annahme, dass es mit dem IO bzw. IO Delay zu tun haben muss, da die HDDs ja deutlich langsamer sind.
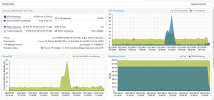
Kleines Beispiel von heute:

Da in den Grafiken teilweise die Peaks abgeflacht werden, werden hier nur knapp 50% IO delay aufgeführt.
Reell auf dem Server waren es aber zeitweise 80-90%. Es ist dann einfach eine andere, nicht beteiligte VM vom PVE gestoppt/gekilled worden.
Auszug Log (hier war das erste auftreten von Meldungen zur entsprechenden VM nachdem ich diese wieder starten wollte, vorher gab es keinerlei Fehler):
Auch das Backup Verzeichnis welches unter /mnt/backup gemountet ist und von einem ganz anderen Server stammt, war aus Sicht des Hosts nicht mehr erreichbar.
Ggf. hat von euch hier jmd. eine Idee, wie man der Ursache noch näher auf die Spur kommen kann bzw. eine generelle Lösung finden kann.
Jede virtuelle Hard Disk mit einem read/write limit auszustatten ist für mich keine gangbare Lösung.
Danke und viele Grüße
esch1986
Ich habe seit geraumer Zeit ein Problem, dass bei hohem IO delay teilweise wahllos VMs crashen bzw. ich vermute den IO delay dahinter.
Zu meinem Setup:
- 3 baugleiche Server (CPU: Intel Xeon E-2176G, RAM: 64GB ECC)
- 2 Server mit 2x1TB SSD
- 1 Server nur 2x4TB HDD
- PVE 6.2-4
- ZFS
zfs_arc_min und zfs_arc_max sind gesetzt:
options zfs zfs_arc_min=4294967296
options zfs zfs_arc_max=8589934592
Ich kann das ganze recht einfach reproduzieren.
Einfach ein großes zip oder rar entpacken und abwarten.
Manchmal crashed die VM die entpackt, manchmal aber auch wahllos eine andere auf dem gleichen Host.
Wenn ich nun hergehe und der virtuellen Hard Disk im PVE UI jeweils read und write limit verpasse (dieses muss dann aber sehr niedrig sein, beispielsweise 20 MB/s), dann läuft alles tip-top durch und keine der VMs crashed.
Hauptsächlich tritt das bei dem Host mit den HDDs auf, ich habe es aber auch geschafft, es bei den SSDs nachzustellen, hier muss die Last auf die Platten aber ungleich größer sein. Daher kam ich auch zu der Annahme, dass es mit dem IO bzw. IO Delay zu tun haben muss, da die HDDs ja deutlich langsamer sind.
Kleines Beispiel von heute:
Da in den Grafiken teilweise die Peaks abgeflacht werden, werden hier nur knapp 50% IO delay aufgeführt.
Reell auf dem Server waren es aber zeitweise 80-90%. Es ist dann einfach eine andere, nicht beteiligte VM vom PVE gestoppt/gekilled worden.
Auszug Log (hier war das erste auftreten von Meldungen zur entsprechenden VM nachdem ich diese wieder starten wollte, vorher gab es keinerlei Fehler):
Code:
Jun 23 08:20:42 proxmox3 pvestatd[2983]: unable to activate storage 'backup' - directory '/mnt/backup' does not exist or is unreachable
Jun 23 08:20:43 proxmox3 pve-firewall[2977]: firewall update time (18.287 seconds)
Jun 23 08:20:43 proxmox3 pvedaemon[24026]: <esc@ldap> end task UPID:proxmox3:00002F42:00DE7045:5EF19F32:qmconfig:302:esc@ldap: OK
Jun 23 08:20:43 proxmox3 pvestatd[2983]: status update time (18.274 seconds)
Jun 23 08:20:44 proxmox3 ntpd[2407]: Soliciting pool server 131.234.137.64
Jun 23 08:20:46 proxmox3 ntpd[2407]: Soliciting pool server 176.9.241.107
Jun 23 08:20:48 proxmox3 pmxcfs[2922]: [status] notice: received log
Jun 23 08:20:52 proxmox3 pvedaemon[16164]: start VM 206: UPID:proxmox3:00003F24:00DE7718:5EF19F44:qmstart:206:esc@ldap:
Jun 23 08:20:52 proxmox3 pvedaemon[20173]: <esc@ldap> starting task UPID:proxmox3:00003F24:00DE7718:5EF19F44:qmstart:206:esc@ldap:
Jun 23 08:20:52 proxmox3 systemd[1]: 206.scope: Succeeded.
Jun 23 08:20:52 proxmox3 systemd[1]: Stopped 206.scope.
Jun 23 08:20:57 proxmox3 pvedaemon[16164]: timeout waiting on systemd
Jun 23 08:20:57 proxmox3 pvedaemon[20173]: <esc@ldap> end task UPID:proxmox3:00003F24:00DE7718:5EF19F44:qmstart:206:esc@ldap: timeout waiting on systemd
Jun 23 08:21:00 proxmox3 systemd[1]: Starting Proxmox VE replication runner...
Jun 23 08:21:00 proxmox3 systemd[1]: pvesr.service: Succeeded.
Jun 23 08:21:00 proxmox3 systemd[1]: Started Proxmox VE replication runner.
Jun 23 08:21:06 proxmox3 pvedaemon[15193]: starting vnc proxy UPID:proxmox3:00003B59:00DE7CBE:5EF19F52:vncproxy:206:esc@ldap:
Jun 23 08:21:06 proxmox3 pvedaemon[20173]: <esc@ldap> starting task UPID:proxmox3:00003B59:00DE7CBE:5EF19F52:vncproxy:206:esc@ldap:
Jun 23 08:21:08 proxmox3 qm[16086]: VM 206 qmp command failed - VM 206 not running
Jun 23 08:21:08 proxmox3 pvedaemon[15193]: Failed to run vncproxy.
Jun 23 08:21:08 proxmox3 pvedaemon[20173]: <esc@ldap> end task UPID:proxmox3:00003B59:00DE7CBE:5EF19F52:vncproxy:206:esc@ldap: Failed to run vncproxy.
Jun 23 08:21:09 proxmox3 pvedaemon[17851]: <esc@ldap> starting task UPID:proxmox3:00004C39:00DE7DB9:5EF19F55:qmstart:206:esc@ldap:
Jun 23 08:21:09 proxmox3 pvedaemon[19513]: start VM 206: UPID:proxmox3:00004C39:00DE7DB9:5EF19F55:qmstart:206:esc@ldap:
Jun 23 08:21:09 proxmox3 ntpd[2407]: Soliciting pool server 176.9.241.107
Jun 23 08:21:11 proxmox3 smartd[1916]: Device: /dev/sda [SAT], SMART Prefailure Attribute: 1 Raw_Read_Error_Rate changed from 81 to 83
Jun 23 08:21:11 proxmox3 smartd[1916]: Device: /dev/sda [SAT], SMART Usage Attribute: 195 Hardware_ECC_Recovered changed from 30 to 32
Jun 23 08:21:11 proxmox3 smartd[1916]: Device: /dev/sdb [SAT], SMART Prefailure Attribute: 1 Raw_Read_Error_Rate changed from 75 to 79
Jun 23 08:21:11 proxmox3 smartd[1916]: Device: /dev/sdb [SAT], SMART Usage Attribute: 195 Hardware_ECC_Recovered changed from 5 to 8
Jun 23 08:21:12 proxmox3 pvedaemon[24401]: starting vnc proxy UPID:proxmox3:00005F51:00DE7EE9:5EF19F58:vncproxy:301:esc@ldap:
Jun 23 08:21:12 proxmox3 pvedaemon[20173]: <esc@ldap> starting task UPID:proxmox3:00005F51:00DE7EE9:5EF19F58:vncproxy:301:esc@ldap:
Jun 23 08:21:13 proxmox3 pvedaemon[24026]: <root@pam> successful auth for user 'monitoring@pve'
Jun 23 08:21:14 proxmox3 pvedaemon[19513]: timeout waiting on systemd
Jun 23 08:21:14 proxmox3 pvedaemon[17851]: <esc@ldap> end task UPID:proxmox3:00004C39:00DE7DB9:5EF19F55:qmstart:206:esc@ldap: timeout waiting on systemdAuch das Backup Verzeichnis welches unter /mnt/backup gemountet ist und von einem ganz anderen Server stammt, war aus Sicht des Hosts nicht mehr erreichbar.
Ggf. hat von euch hier jmd. eine Idee, wie man der Ursache noch näher auf die Spur kommen kann bzw. eine generelle Lösung finden kann.
Jede virtuelle Hard Disk mit einem read/write limit auszustatten ist für mich keine gangbare Lösung.
Danke und viele Grüße
esch1986
Last edited: