Hi
I've been doing a lot of reading and a bit of experimentation with Proxmox this week and have a bit of a strange situation, in terms of performance.
I manage the network of a large school, and we've been using Hyper-V for a few years with Storage Spaces Tiered Storage local to our hypervisors, then using hyper-v replication for failover.
We have recently purchased a new server to replace one of our older hypervisors, a Dell R7515, and in the process of configuring it I've been taking the opportunity to have a play with Proxmox to see what the state of play is with it, and whether we should move across.
It's loaded with 12x 3tb SAS drives and a couple of intel p3520 NVME 1.2TB SSDs. The server has 128gb of 3200 ECC RAM, and an Epyc 7313p processor.
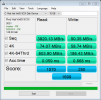
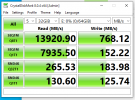
I span it up with Windows to start with and got some baseline numbers using the Perc H740P in raid 6 mode across the 12x3tb drives and get very solid numbers - running a 10GB test using AS SSD Benchmark I get 2300 mb/s sequential writes.
I put the Perc card in HBA mode, and installed Proxmox 7.0-8 on a Raid Z2 ZFS disk spanned across the 12 3tb disks (with default settings as set by the proxmox installer), then spun up a windows VM (using a virtio SCSI disk in no cache mode) so that I could run the AS SSD Benchmark app and get some comparative testing.
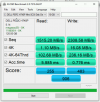
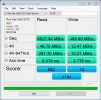
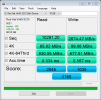
Running the AS SSD Benchmark it starts very quick, but the write speed then hits an absolute cliff and grinds to a near halt, giving a sequential write speed of 50mb/s - this gets stranger as the 4k write speed is actually faster at nearly 59mb/s and 4k 64 thread write speed at 186 mb/s (I'm imagining this is perhaps because the AS SSD benchmark does 10gb for the sequential test but a smaller amount of data for the 4k tests so hasn't hit the write speed cliff perhaps?)
If I run the test with a smaller amount of data you can see the speed before it falls off a cliff - with a 1gb AS SSD test the sequential write speed is 3300mb/s (!), 3gb test the sequential write result is already down to 183 mb/s and so on until the 50mb/s shown with the 10gb test.
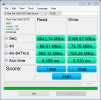
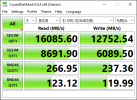
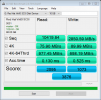
I will caveat here that I appreciate this is a somewhat unfair test as the previous windows install had native disk access instead of virtualized, however testing against one of the Intel SSDs I found sequential write performance to be very comparable, 1333 mb/s native write speed in windows against 1232mb/s virtualized on proxmox.
I've done a bit of benchmarking on Proxmox using DD to try and give ZFS a fairer shake, and performance is a fair bit better but still well behind the Raid 6 performance - so the command:
dd if=/dev/zero of=/root/testfile2 bs=10G count=1 iflag=fullblock oflag=dsync
I get 344mb/s with ZFS compression turned off (2gb/s with compression on but this is obviously a bit of a poor test as zeros are very compressible!)
using the harder random data based test
dd if=/dev/urandom of=/root/testfile4 bs=10G count=1 iflag=fullblock oflag=dsync
the resultant speed is 171mb/s (compression still off).
For comparison running those tests against one of the intel SSDs i get 2.7gb/s for the zeroes, 294mb/s for the urandom data (SSD controller compression no doubt coming into play with the zero data there, speed of urandom generation perhaps capping the speed of the other test so neither test perfect!)
So, what's going on? I did anticipate RaidZ2 would be a bit slower in the writes but these writes seem painful - and random writes being faster seems very strange indeed!
Obviously read speeds are great but this is hugely skewed by the dataset fitting easily within the ARC, won't really know how reads behave until our production load is spun up.
I've been doing a lot of reading and a bit of experimentation with Proxmox this week and have a bit of a strange situation, in terms of performance.
I manage the network of a large school, and we've been using Hyper-V for a few years with Storage Spaces Tiered Storage local to our hypervisors, then using hyper-v replication for failover.
We have recently purchased a new server to replace one of our older hypervisors, a Dell R7515, and in the process of configuring it I've been taking the opportunity to have a play with Proxmox to see what the state of play is with it, and whether we should move across.
It's loaded with 12x 3tb SAS drives and a couple of intel p3520 NVME 1.2TB SSDs. The server has 128gb of 3200 ECC RAM, and an Epyc 7313p processor.
I span it up with Windows to start with and got some baseline numbers using the Perc H740P in raid 6 mode across the 12x3tb drives and get very solid numbers - running a 10GB test using AS SSD Benchmark I get 2300 mb/s sequential writes.
I put the Perc card in HBA mode, and installed Proxmox 7.0-8 on a Raid Z2 ZFS disk spanned across the 12 3tb disks (with default settings as set by the proxmox installer), then spun up a windows VM (using a virtio SCSI disk in no cache mode) so that I could run the AS SSD Benchmark app and get some comparative testing.
Running the AS SSD Benchmark it starts very quick, but the write speed then hits an absolute cliff and grinds to a near halt, giving a sequential write speed of 50mb/s - this gets stranger as the 4k write speed is actually faster at nearly 59mb/s and 4k 64 thread write speed at 186 mb/s (I'm imagining this is perhaps because the AS SSD benchmark does 10gb for the sequential test but a smaller amount of data for the 4k tests so hasn't hit the write speed cliff perhaps?)
If I run the test with a smaller amount of data you can see the speed before it falls off a cliff - with a 1gb AS SSD test the sequential write speed is 3300mb/s (!), 3gb test the sequential write result is already down to 183 mb/s and so on until the 50mb/s shown with the 10gb test.
I will caveat here that I appreciate this is a somewhat unfair test as the previous windows install had native disk access instead of virtualized, however testing against one of the Intel SSDs I found sequential write performance to be very comparable, 1333 mb/s native write speed in windows against 1232mb/s virtualized on proxmox.
I've done a bit of benchmarking on Proxmox using DD to try and give ZFS a fairer shake, and performance is a fair bit better but still well behind the Raid 6 performance - so the command:
dd if=/dev/zero of=/root/testfile2 bs=10G count=1 iflag=fullblock oflag=dsync
I get 344mb/s with ZFS compression turned off (2gb/s with compression on but this is obviously a bit of a poor test as zeros are very compressible!)
using the harder random data based test
dd if=/dev/urandom of=/root/testfile4 bs=10G count=1 iflag=fullblock oflag=dsync
the resultant speed is 171mb/s (compression still off).
For comparison running those tests against one of the intel SSDs i get 2.7gb/s for the zeroes, 294mb/s for the urandom data (SSD controller compression no doubt coming into play with the zero data there, speed of urandom generation perhaps capping the speed of the other test so neither test perfect!)
So, what's going on? I did anticipate RaidZ2 would be a bit slower in the writes but these writes seem painful - and random writes being faster seems very strange indeed!
Obviously read speeds are great but this is hugely skewed by the dataset fitting easily within the ARC, won't really know how reads behave until our production load is spun up.