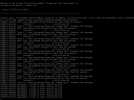
Hello, I've recently tried to open up my proxmox gui and noticed i couldn't connect to it. When i opened up the terminal i was greeted by two a few different errors.
1.
INFO: task pmxcfs:1916 blocked for more than 120 seconds
INFO: task java:6969xx blocked for more than 120 seconds (the xx meaning there were a few of these.)
INFO: task kworker/u129:x:xxxxx blocked for more than 120 seconds
at the end of those theres a bunch of systemd[1]: failed to start journal service.
Because of these errors i cant get into the console to get logs or ssh in to get logs either since it times out, however all the VMs that were running in proxmox are up and working as normal.
Anyone know where i should go from here?
1.
INFO: task pmxcfs:1916 blocked for more than 120 seconds
INFO: task java:6969xx blocked for more than 120 seconds (the xx meaning there were a few of these.)
INFO: task kworker/u129:x:xxxxx blocked for more than 120 seconds
at the end of those theres a bunch of systemd[1]: failed to start journal service.
Because of these errors i cant get into the console to get logs or ssh in to get logs either since it times out, however all the VMs that were running in proxmox are up and working as normal.
Anyone know where i should go from here?