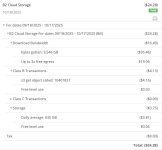
Shortly after PBS 4.0 came out, I configured a S3 backup datastore for about 600GB of data. I had verification, prune, and garbage collection jobs running daily after my backup completed. I got a surprise bill 5x my typical amount after configuring PBS to use my Backblaze S3 bucket. The verification jobs always ran for multiple hours each day, even with minimal backup change rate. As you can see in my bill, PBS downloaded 3.5TB of data over the month, even though I did zero restores. It also made 10 MILLION s3 get object requests. I also saw on my internet usage via my IPS and firewall that PBS was using massive amounts of bandwidth during those verification jobs.
I've used Synology Hyperbackup for another Backblaze S3 bucket, and it's highly efficient in terms of egress and API transactions. I had over 1TB of data, and not once did my download bandwidth or API fees cost me anything. It was so efficient, that even nightly backups and verification were basically free. Needless to say, I disabled the PBS S3 as it is cost prohibitive.

I've used Synology Hyperbackup for another Backblaze S3 bucket, and it's highly efficient in terms of egress and API transactions. I had over 1TB of data, and not once did my download bandwidth or API fees cost me anything. It was so efficient, that even nightly backups and verification were basically free. Needless to say, I disabled the PBS S3 as it is cost prohibitive.