Hi, we have a weird issue configuring a Hyper Converged Cluster using Fabrics:
blue: Cluster, Green: CephStor

After creating two Fabrics, one for Ceph and one for Cluster

The CephStor Fabric is working fine. If I deactivate vmbr2 (bond of ens1f1np1 and ens2f1np1) I can ping from shadlpven00 through sshadlpven01 to sshadlpven02.

not the fastes but looking okay so far.
otherwise in the Cluster Fabric if deactivate vmbr4 (vmbr 4=ens3f2) and try to ping sshadlpven02 (172.16.241.3) from shadlpven00 through sshadlpven01, the target host is unreachable

Now comes the fun part:
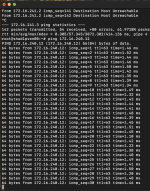
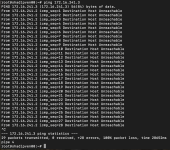
If I start a Ping from sshadlpven01 to sshadlpven02 (172.16.241.3), the ping from shadlpven00 to sshadlpven02 starts working!

just to stop soon after (upper windows in the screenshot below), but not immediately, after i stop the ping from sshadlpven01

no idea whats wrong with it. We tried all sorts of variations.. interface + bond, interface + bond + vmbr on top. All are working fine, until we take a port / bond / vmbr ofline and the rerouting happens. In that case the traffic is correctly rerouted to the other node, but from there not forwarded. As I said.. no idea why. Configuration looks fine to me. CephStor is working flawless, only the second fabric is affected.
blue: Cluster, Green: CephStor
After creating two Fabrics, one for Ceph and one for Cluster
The CephStor Fabric is working fine. If I deactivate vmbr2 (bond of ens1f1np1 and ens2f1np1) I can ping from shadlpven00 through sshadlpven01 to sshadlpven02.
not the fastes but looking okay so far.
otherwise in the Cluster Fabric if deactivate vmbr4 (vmbr 4=ens3f2) and try to ping sshadlpven02 (172.16.241.3) from shadlpven00 through sshadlpven01, the target host is unreachable
Now comes the fun part:
If I start a Ping from sshadlpven01 to sshadlpven02 (172.16.241.3), the ping from shadlpven00 to sshadlpven02 starts working!
just to stop soon after (upper windows in the screenshot below), but not immediately, after i stop the ping from sshadlpven01
no idea whats wrong with it. We tried all sorts of variations.. interface + bond, interface + bond + vmbr on top. All are working fine, until we take a port / bond / vmbr ofline and the rerouting happens. In that case the traffic is correctly rerouted to the other node, but from there not forwarded. As I said.. no idea why. Configuration looks fine to me. CephStor is working flawless, only the second fabric is affected.
Code:
root@shadlpven00:~# cat /etc/frr/frr.conf
frr version 10.3.1
frr defaults datacenter
hostname shadlpven00
log syslog informational
service integrated-vtysh-config
!
router openfabric CephStor
net 49.0001.1720.1624.0009.00
exit
!
router openfabric Cluster
net 49.0001.1720.1624.0009.00
exit
!
interface dummy_CephStor
ip router openfabric CephStor
openfabric passive
exit
!
interface dummy_Cluster
ip router openfabric Cluster
openfabric passive
exit
!
interface vmbr1
ip router openfabric CephStor
openfabric hello-interval 1
openfabric csnp-interval 2
exit
!
interface vmbr2
ip router openfabric CephStor
openfabric hello-interval 1
openfabric csnp-interval 2
exit
!
interface vmbr3
ip router openfabric Cluster
openfabric hello-interval 1
openfabric csnp-interval 2
exit
!
interface vmbr4
ip router openfabric Cluster
openfabric hello-interval 1
openfabric csnp-interval 2
exit
!
access-list pve_openfabric_CephStor_ips permit 172.16.240.8/29
!
access-list pve_openfabric_Cluster_ips permit 172.16.241.0/24
!
route-map pve_openfabric permit 100
match ip address pve_openfabric_CephStor_ips
set src 172.16.240.9
exit
!
route-map pve_openfabric permit 110
match ip address pve_openfabric_Cluster_ips
set src 172.16.241.1
exit
!
ip protocol openfabric route-map pve_openfabric
!
!
line vtyAttachments
Last edited:

