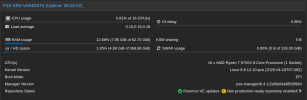
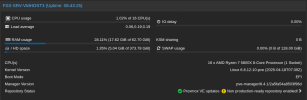
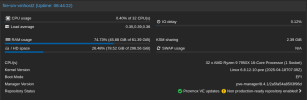
I have a 3 node PVE 8 + Ceph cluster, community update server. I've previously seen some instability before with restarts and network disruption, but my last batch of updates crashed every other node in the cluster, for each server I commanded a reboot on. As yet I've failed to pull anything helpful out of my logs, though I'm unclear if that's b/c I need to configure additional logging to catch this. Servers mostly just crash and reboot, though I've also seen them hang fully unresponsive with no video output. Minimal customization, beyond enabling root ZFS encryption and securing ceph and migration traffic with IPSec.
I have a 4th non-clustered server with an otherwise very similar config which has been perfectly stable. The crashing seems to be exacerbated by network issues, I've previously seen crashes when a network fault causes links to flap. Crashing got much worse after I set up link aggregations for all 3 nodes, though notably the stable server is connected to the same switches with the same config. All 3 of the problem servers have ConnectX 4 NICs, the stable one is a ConnectX 3 NIC; various AMD Ryzen CPUs in a spattering of consumer ASUS boards, limited hardware commonality aside from that. I've also reproduced the crash after pulling network cables - this is a little less consistent and doesn't typically crash all nodes. Crash happens maybe 30-60 seconds after the network disruption or initiating the reboot on another node.
It's possible my choice to re-use the cluster-managed certificates for IPSec could be causing this?The cluster filesystem mount in /etc/pve/ becomes at least partially unavailable when quorum is lost IIRC, and I don't see a more stable location to reference the root certificate from than /etc/pve/pve-root-ca.pem.
I have a 4th non-clustered server with an otherwise very similar config which has been perfectly stable. The crashing seems to be exacerbated by network issues, I've previously seen crashes when a network fault causes links to flap. Crashing got much worse after I set up link aggregations for all 3 nodes, though notably the stable server is connected to the same switches with the same config. All 3 of the problem servers have ConnectX 4 NICs, the stable one is a ConnectX 3 NIC; various AMD Ryzen CPUs in a spattering of consumer ASUS boards, limited hardware commonality aside from that. I've also reproduced the crash after pulling network cables - this is a little less consistent and doesn't typically crash all nodes. Crash happens maybe 30-60 seconds after the network disruption or initiating the reboot on another node.
It's possible my choice to re-use the cluster-managed certificates for IPSec could be causing this?
Last edited: