I have been setting up a new home server with a brand new proxmox installation. I have been getting about 5 lockups today during which the whole system hangs and produces page faults.
I don't know how to copy the text of the page fault, but I have attached it as a picture. If I can get that copied as text somehow please let me know.
PVE is running the latest version:
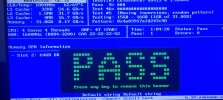
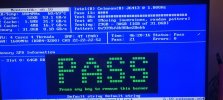
I have completed a full memtest86+ test with zero errors.
Full dmesg output is included as well, please let me know what else to add.
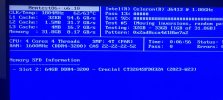
System is running on an Intel J6413 CPU
I don't know how to copy the text of the page fault, but I have attached it as a picture. If I can get that copied as text somehow please let me know.
PVE is running the latest version:
Code:
root@pve:~# pveversion
pve-manager/8.0.3/bbf3993334bfa916 (running kernel: 6.2.16-3-pve)I have completed a full memtest86+ test with zero errors.
Full dmesg output is included as well, please let me know what else to add.
System is running on an Intel J6413 CPU