Hi there,
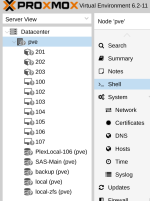
Over the last week, the GUI has been showing gray question marks over each LXC, VM and storage (screenshot attached). Running
brings the GUI back to normal for ~5 - 10mins, and then it reverts back to displaying question marks. Within the last two days, two more things have started to occur:
Thank you
Additional details:
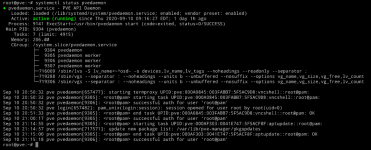
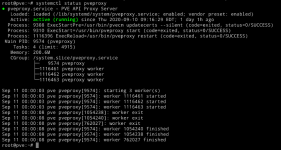
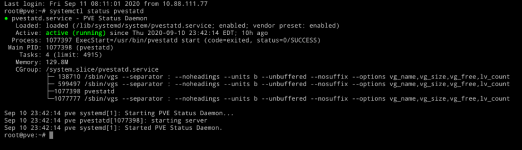
Syslog does not show anything out of the ordinary, except the following, occuring ~every 10 minutes (this server is not part of a cluster):
Over the last week, the GUI has been showing gray question marks over each LXC, VM and storage (screenshot attached). Running
Code:
systemctl pvstatd restart- Generally overnight, Proxmox will freeze (unable to access the GUI, returns a 'page not found' error). I'm able to log in via SSH but commands hang indefinitely.
- Several times, my entire network (including independent devices on my wifi network) has lost its connection to the internet and the network when I am working to troubleshoot the above issues
Thank you
Additional details:
Syslog does not show anything out of the ordinary, except the following, occuring ~every 10 minutes (this server is not part of a cluster):
Code:
Sep 10 20:59:43 pve ceph-crash[8480]: WARNING:__main__:post /var/lib/ceph/crash/2019-11-16_02:55:22.99375[...] as client.crash.pve failed: [errno 2] error connecting to the cluster| Kernel Version: Linux 5.4.60-1-pve #1 SMP PVE 5.4.60-1 (Mon, 31 Aug 2020 10:36:22 +0200) |
| PVE Manager Version: pve-manager/6.2-11/22fb4983 |
- r710, dual X5675, 48GB RAM, and a PERC H700 Raid Controller
- 1 x 500GB SSD ZFS with compression (running Proxmox and VM images)
- 2 x 2 TB 7200RPM SAS drives LVM RAID0 (for storage)
- 1 x 2 TB 7200RPM LVM drive (for storage)
- Running 2 Windows Server 2019 VMs, 2 Ubuntu VMs, 2 Alpine Linux LXCs