Hello everyone,
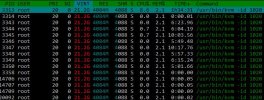
I have a problem with RAM consumption on proxmox nodes. For example there is one node with a total of 192GB RAM and virtual machines with balooning devices running with a max memory total of 64GB RAM. Though the system has about 140GB RAM in use, the rest is buffered/cached and free ram is nearly not there at all. I can see in htop that nearly all VMs have a VIRT Ram of more than the max size of they memory. Also the systems even starts to use the 8GB of the swap so that it becomes very unresponsive.
First I suspected that the NUMA settings were the problem. We use dual socket nodes and enabled always two sockets for a VM instead of one socket. Though that did not fix the issue.
Does anybody know what could be wrong here? I´ll glady provide more details if required.
Greetings,
Thomas
PS: that free -m was taken after rebooting some VMs that used up alot of swap (used smem to find out) Also I kept a few VMs shutdown.
I have a problem with RAM consumption on proxmox nodes. For example there is one node with a total of 192GB RAM and virtual machines with balooning devices running with a max memory total of 64GB RAM. Though the system has about 140GB RAM in use, the rest is buffered/cached and free ram is nearly not there at all. I can see in htop that nearly all VMs have a VIRT Ram of more than the max size of they memory. Also the systems even starts to use the 8GB of the swap so that it becomes very unresponsive.
First I suspected that the NUMA settings were the problem. We use dual socket nodes and enabled always two sockets for a VM instead of one socket. Though that did not fix the issue.
Does anybody know what could be wrong here? I´ll glady provide more details if required.
Greetings,
Thomas
PS: that free -m was taken after rebooting some VMs that used up alot of swap (used smem to find out) Also I kept a few VMs shutdown.
Code:
total used free shared buff/cache available
Mem: 192089 147078 7507 368 37503 43216
Swap: 8191 1818 6373Attachments
Last edited:
