Hallo zusammen,
ich habe mein Cluster - bestehend aus 3 Nodes - heute vom 8.0.x auf 8.2.3 über die GUI upgedatet. Für die ersten beiden Nodes ist das Update erfolgreich durchgelaufen und auch der Neustart konnte erfolgreich durchgeführt werden. Beim Update des dritten Nodes ist irgendwann - vermutlich vor erfolgreichem Abschluss des Updates - die Verbindung zur Shell unterbrochen worden. Ich habe danach den betroffenen Node neu gestartet, jedoch wird nicht im Datacenter erkannt. Per Mail habe ich folgende Nachricht vom dritten Node erhalten:
The node 'pvenode01' failed and needs manual intervention.
The PVE HA manager tries to fence it and recover the configured HA resources to a healthy node if possible.
Current fence status: FENCE
Try to fence node 'pvenode01'
"manager_status": {
"master_node": "pvenode03",
"node_status": {
"pvenode01": "unknown",
"pvenode02": "online",
"pvenode03": "online"
},
"service_status": {
"ct:119": {
"node": "pvenode03",
"running": 1,
"state": "started",
"uid": "DeHyPFsOu7Ft/mi0P3uaAg"
},
"ct:120": {
"node": "pvenode02",
"running": 1,
"state": "started",
"uid": "892+RumzygBC/MIQdX1N+w"
},
"vm:100": {
"node": "pvenode02",
"running": 1,
"state": "started",
"uid": "qme3iDs9FMmBB0j8riO1sg"
},
"vm:101": {
"node": "pvenode02",
"running": 1,
"state": "started",
"uid": "A0ktFvdlYiYkTvdrJ9Vs7w"
},
"vm:102": {
"node": "pvenode02",
"running": 1,
"state": "started",
"uid": "jO8DcWhdhfBw/K6IH4cuqA"
},
"vm:105": {
"node": "pvenode03",
"running": 1,
"state": "started",
"uid": "aCCpNUjOumu2ybqA0UybHw"
},
"vm:106": {
"node": "pvenode03",
"state": "stopped",
"uid": "z6ahjyvSPgAPFmc5dw8g3A"
},
"vm:107": {
"node": "pvenode02",
"running": 1,
"state": "started",
"uid": "c9iHH3e/7jBw/5+hjNZVpA"
},
"vm:108": {
"node": "pvenode02",
"running": 1,
"state": "started",
"uid": "S4INUoyBCFZ0t+YqjRgn+g"
},
"vm:109": {
"node": "pvenode03",
"running": 1,
"state": "started",
"uid": "ZhE9555Akqs2gVypPQbyzw"
},
"vm:112": {
"node": "pvenode01",
"state": "stopped",
"uid": "TitN9q+67mBk7AB/1gWurw"
},
"vm:113": {
"node": "pvenode02",
"running": 1,
"state": "started",
"uid": "+pFjCrvyBslfGaKcPsllEQ"
},
"vm:115": {
"node": "pvenode03",
"running": 1,
"state": "started",
"uid": "4gpAfmW+QP+d6zVd7Bh8Sg"
},
"vm:116": {
"node": "pvenode02",
"running": 1,
"state": "started",
"uid": "JVhLhvwF5AFjyMTPF6BoDA"
},
"vm:118": {
"node": "pvenode03",
"running": 1,
"state": "started",
"uid": "AGiaXixcvLRHs21KUycvbQ"
}
},
"timestamp": 1723835449
},
"node_status": {
"pvenode01": "fence",
"pvenode02": "online",
"pvenode03": "online"
}
}
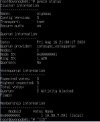
Wenn ich mich am fehlerhaften Node anmelde und den Status vom PVE Cluster Manager anzeigen lasse (pvecm status), kommt die Meldung wie im angehängten Screenshot.
Wenn ich den Status über einen der beiden intakten Nodes anzeigen lasse, kommt folgende Meldung:
root@pvenode02:~# pvecm status
Cluster information
-------------------
Name: olympus
Config Version: 3
Transport: knet
Secure auth: on
Quorum information
------------------
Date: Fri Aug 16 21:57:11 2024
Quorum provider: corosync_votequorum
Nodes: 2
Node ID: 0x00000002
Ring ID: 2.a37
Quorate: Yes
Votequorum information
----------------------
Expected votes: 3
Highest expected: 3
Total votes: 2
Quorum: 2
Flags: Quorate
Membership information
----------------------
Nodeid Votes Name
0x00000002 1 10.30.7.202 (local)
0x00000003 1 10.30.7.203
Kann hier jemand unterstützen?
Viele Grüße
ich habe mein Cluster - bestehend aus 3 Nodes - heute vom 8.0.x auf 8.2.3 über die GUI upgedatet. Für die ersten beiden Nodes ist das Update erfolgreich durchgelaufen und auch der Neustart konnte erfolgreich durchgeführt werden. Beim Update des dritten Nodes ist irgendwann - vermutlich vor erfolgreichem Abschluss des Updates - die Verbindung zur Shell unterbrochen worden. Ich habe danach den betroffenen Node neu gestartet, jedoch wird nicht im Datacenter erkannt. Per Mail habe ich folgende Nachricht vom dritten Node erhalten:
The node 'pvenode01' failed and needs manual intervention.
The PVE HA manager tries to fence it and recover the configured HA resources to a healthy node if possible.
Current fence status: FENCE
Try to fence node 'pvenode01'
Overall Cluster status:
{"manager_status": {
"master_node": "pvenode03",
"node_status": {
"pvenode01": "unknown",
"pvenode02": "online",
"pvenode03": "online"
},
"service_status": {
"ct:119": {
"node": "pvenode03",
"running": 1,
"state": "started",
"uid": "DeHyPFsOu7Ft/mi0P3uaAg"
},
"ct:120": {
"node": "pvenode02",
"running": 1,
"state": "started",
"uid": "892+RumzygBC/MIQdX1N+w"
},
"vm:100": {
"node": "pvenode02",
"running": 1,
"state": "started",
"uid": "qme3iDs9FMmBB0j8riO1sg"
},
"vm:101": {
"node": "pvenode02",
"running": 1,
"state": "started",
"uid": "A0ktFvdlYiYkTvdrJ9Vs7w"
},
"vm:102": {
"node": "pvenode02",
"running": 1,
"state": "started",
"uid": "jO8DcWhdhfBw/K6IH4cuqA"
},
"vm:105": {
"node": "pvenode03",
"running": 1,
"state": "started",
"uid": "aCCpNUjOumu2ybqA0UybHw"
},
"vm:106": {
"node": "pvenode03",
"state": "stopped",
"uid": "z6ahjyvSPgAPFmc5dw8g3A"
},
"vm:107": {
"node": "pvenode02",
"running": 1,
"state": "started",
"uid": "c9iHH3e/7jBw/5+hjNZVpA"
},
"vm:108": {
"node": "pvenode02",
"running": 1,
"state": "started",
"uid": "S4INUoyBCFZ0t+YqjRgn+g"
},
"vm:109": {
"node": "pvenode03",
"running": 1,
"state": "started",
"uid": "ZhE9555Akqs2gVypPQbyzw"
},
"vm:112": {
"node": "pvenode01",
"state": "stopped",
"uid": "TitN9q+67mBk7AB/1gWurw"
},
"vm:113": {
"node": "pvenode02",
"running": 1,
"state": "started",
"uid": "+pFjCrvyBslfGaKcPsllEQ"
},
"vm:115": {
"node": "pvenode03",
"running": 1,
"state": "started",
"uid": "4gpAfmW+QP+d6zVd7Bh8Sg"
},
"vm:116": {
"node": "pvenode02",
"running": 1,
"state": "started",
"uid": "JVhLhvwF5AFjyMTPF6BoDA"
},
"vm:118": {
"node": "pvenode03",
"running": 1,
"state": "started",
"uid": "AGiaXixcvLRHs21KUycvbQ"
}
},
"timestamp": 1723835449
},
"node_status": {
"pvenode01": "fence",
"pvenode02": "online",
"pvenode03": "online"
}
}
Wenn ich mich am fehlerhaften Node anmelde und den Status vom PVE Cluster Manager anzeigen lasse (pvecm status), kommt die Meldung wie im angehängten Screenshot.
Wenn ich den Status über einen der beiden intakten Nodes anzeigen lasse, kommt folgende Meldung:
root@pvenode02:~# pvecm status
Cluster information
-------------------
Name: olympus
Config Version: 3
Transport: knet
Secure auth: on
Quorum information
------------------
Date: Fri Aug 16 21:57:11 2024
Quorum provider: corosync_votequorum
Nodes: 2
Node ID: 0x00000002
Ring ID: 2.a37
Quorate: Yes
Votequorum information
----------------------
Expected votes: 3
Highest expected: 3
Total votes: 2
Quorum: 2
Flags: Quorate
Membership information
----------------------
Nodeid Votes Name
0x00000002 1 10.30.7.202 (local)
0x00000003 1 10.30.7.203
Kann hier jemand unterstützen?
Viele Grüße