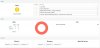
I setup a proxmox cluster with 3 identical Xeon-D systems with 64GB ram, each one has a 1TB Samsung 970 Pro commercial drive and a 6.4TB Intel DC P4600 drive. Based on feedback here I, I had no issues setting up the cluster and installing ceph. Once I setup Ceph and started to added the OSDs, I got one that went Down but stayed in.
I've seen a couple of messages in the logs about heartbeat not being received but I've run ping on all of the nodes for 20 minutes and only lost 1 on one of the nodes, the rest were at 100% with latency at .1 - .15 ms.
One of the messages is Health check failed: 2 slow ops, I'm not sure what those are. I haven't had any issues with these system and ran a 12 hour burn in on the nodes and drive to see if the "limited" test discovered any issues.
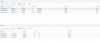
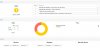
While typing this, there was a state change and then osd came back up for about 5 minutes. I included an updated picture and a snip of the syslog.
Please let me know if other logs are more helpful and/or which commands to run to troubleshoot it.
I've seen a couple of messages in the logs about heartbeat not being received but I've run ping on all of the nodes for 20 minutes and only lost 1 on one of the nodes, the rest were at 100% with latency at .1 - .15 ms.
One of the messages is Health check failed: 2 slow ops, I'm not sure what those are. I haven't had any issues with these system and ran a 12 hour burn in on the nodes and drive to see if the "limited" test discovered any issues.
While typing this, there was a state change and then osd came back up for about 5 minutes. I included an updated picture and a snip of the syslog.
Please let me know if other logs are more helpful and/or which commands to run to troubleshoot it.