I upgraded a Proxmox 6.2 Cluster to the new Proxmox 6.3 and after I rebooted the nodes I am seeing some really strange load issues. I am mostly running LXC containers on the host and after they all boot up the load on the box just keeps climbing to insane numbers. I have to stop the LXC containers to get the load on the box to come back to normal.
The LXC containers are using both Ceph (octopus) storage and local disks. I am not sure if this is related to Octopus being upgraded as well, or some strange software bug with the LXC or something related?
The strange part is that the CPU usage stays low, but the LOAD just keeps climbing? Any ideas on what i should look at to troubleshoot this? It seems to be affecting all my hosts in the cluster after i rebooted them. They were fine until the reboot.
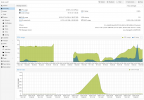
See the attached pic of version numbers and Interface screenshot!!!
NOTE: I did notice that i had a temporary MTU issue with 2 of the hosts, I have corrected it however I am still seeing some strangeness. I do have corosync configured to use 2 networks to do the health check over. Would there be an issue with one of the networks using LACP and the other one just being active-passive bond?
My corosync config is like this:
nodelist {
node {
name: pve01
nodeid: 1
quorum_votes: 1
ring0_addr: pve01
ring1_addr: pve01-int
}
node {
name: pve02
nodeid: 2
quorum_votes: 1
ring0_addr: pve02
ring1_addr: pve02-int
}
node {
name: pve03
nodeid: 3
quorum_votes: 1
ring0_addr: pve03
ring1_addr: pve03-int
}
node {
name: pve04
nodeid: 4
quorum_votes: 1
ring0_addr: pve04
ring1_addr: pve04-int
}
}
quorum {
provider: corosync_votequorum
}
totem {
cluster_name: cluster1
config_version: 25
interface {
ringnumber: 0
}
interface {
ringnumber: 1
}
ip_version: ipv4
secauth: on
transport: knet
version: 2
}
Would there be a way to see why starting 20 LXC instances causes the load to go crazy?
The LXC containers are using both Ceph (octopus) storage and local disks. I am not sure if this is related to Octopus being upgraded as well, or some strange software bug with the LXC or something related?
The strange part is that the CPU usage stays low, but the LOAD just keeps climbing? Any ideas on what i should look at to troubleshoot this? It seems to be affecting all my hosts in the cluster after i rebooted them. They were fine until the reboot.
See the attached pic of version numbers and Interface screenshot!!!
NOTE: I did notice that i had a temporary MTU issue with 2 of the hosts, I have corrected it however I am still seeing some strangeness. I do have corosync configured to use 2 networks to do the health check over. Would there be an issue with one of the networks using LACP and the other one just being active-passive bond?
My corosync config is like this:
nodelist {
node {
name: pve01
nodeid: 1
quorum_votes: 1
ring0_addr: pve01
ring1_addr: pve01-int
}
node {
name: pve02
nodeid: 2
quorum_votes: 1
ring0_addr: pve02
ring1_addr: pve02-int
}
node {
name: pve03
nodeid: 3
quorum_votes: 1
ring0_addr: pve03
ring1_addr: pve03-int
}
node {
name: pve04
nodeid: 4
quorum_votes: 1
ring0_addr: pve04
ring1_addr: pve04-int
}
}
quorum {
provider: corosync_votequorum
}
totem {
cluster_name: cluster1
config_version: 25
interface {
ringnumber: 0
}
interface {
ringnumber: 1
}
ip_version: ipv4
secauth: on
transport: knet
version: 2
}
Would there be a way to see why starting 20 LXC instances causes the load to go crazy?
Attachments
Last edited:
")