Moin zusammen
Ich plane zur Zeit einen neuen Proxmox Cluster. Dieser wird wahrscheinlich aus 4 Hosts bestehen. Mich treibt die Frage um, wie ich den Storage am besten designen könnte. Zur Zeit nutzen wir Ceph. Obwohl ich Ceph wirklich super finde, was die Sicherheit und "ease of use" angeht, ist es uns nicht performant genug, gerade was die IOps angeht. Wir haben ein paar Datenbanken und die leiden sehr unter Ceph.
Daher habe ich mir heute mal ZFS angeschaut und mir mal gedanken zu 2 Lösungsszenarien gemacht. Ich hätte dazu gerne Input udn Erfahrungswert, ob die Designs Sinnvoll sind und welches davon vll besser ist.
Design 1:
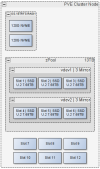
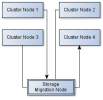
Jeder Node bekommt seinen eigenen ZFS Storage. Design so wie im Anhang "Node Storage Design" gezeigt. Das Gäbe vermutlich die beste Performance, da IO Lokal stattfindet. Live Migration könnten wir lösen, indem wir vor einer Migration die VM-Images auf einen zentralen migration Storage schieben. Dieser hat das gleiche Layout wie ein einzelner Node, stellt aber nur Storage für die Migration zur Verfügung, siehe Anhang "Cluster Storage Migration Design" und wäre per NFS als shared Storage angebunden.
Vorteile:
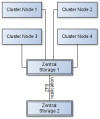
Die Nodes haben, bis auf für das OS, gar keinen eigenen Storage, sondern nutzen einen zentralen redundanten Storage Server, der z.B. via 25Gbit Ethernet angebunden ist (Siehe Anhang "Cluster Central Storage Design). Die Redundanz wäre dann pro Storage Node ein 2Way Mirror, statt wie bei Design 1 ein 3Way Mirror. Dafür gäbe es aber einen zweiten Storage Server, auf den der erste repliziert wird.
Vorteile:
Habt ihr Anregungen? Ideen? Verbesserungsvorschläge? No Gos?
Ich plane zur Zeit einen neuen Proxmox Cluster. Dieser wird wahrscheinlich aus 4 Hosts bestehen. Mich treibt die Frage um, wie ich den Storage am besten designen könnte. Zur Zeit nutzen wir Ceph. Obwohl ich Ceph wirklich super finde, was die Sicherheit und "ease of use" angeht, ist es uns nicht performant genug, gerade was die IOps angeht. Wir haben ein paar Datenbanken und die leiden sehr unter Ceph.
Daher habe ich mir heute mal ZFS angeschaut und mir mal gedanken zu 2 Lösungsszenarien gemacht. Ich hätte dazu gerne Input udn Erfahrungswert, ob die Designs Sinnvoll sind und welches davon vll besser ist.
Design 1:
Jeder Node bekommt seinen eigenen ZFS Storage. Design so wie im Anhang "Node Storage Design" gezeigt. Das Gäbe vermutlich die beste Performance, da IO Lokal stattfindet. Live Migration könnten wir lösen, indem wir vor einer Migration die VM-Images auf einen zentralen migration Storage schieben. Dieser hat das gleiche Layout wie ein einzelner Node, stellt aber nur Storage für die Migration zur Verfügung, siehe Anhang "Cluster Storage Migration Design" und wäre per NFS als shared Storage angebunden.
Vorteile:
- Höchste Performance
- Bei Ausfall eines Nodes, können Maschinen nicht innerhalb weniger Minuten auf einem anderen Node hochgefahren werden, da shared Storage nur für die Migration verwendet wird.
Die Nodes haben, bis auf für das OS, gar keinen eigenen Storage, sondern nutzen einen zentralen redundanten Storage Server, der z.B. via 25Gbit Ethernet angebunden ist (Siehe Anhang "Cluster Central Storage Design). Die Redundanz wäre dann pro Storage Node ein 2Way Mirror, statt wie bei Design 1 ein 3Way Mirror. Dafür gäbe es aber einen zweiten Storage Server, auf den der erste repliziert wird.
Vorteile:
- Shared Storage
- problemlose Live Migration
- schnelles Hochfahren von VMs auf anderen Nodes, wenn ein Node ausfällt
- Ggf Kosteneffektiver?
- Backups könnten vll vom Storage Server 2 gezogen werden, was die Performance dann im Betrieb nicht beeinflusst? (Bin nicht sicher, ob man das mit Proxmox Backup Server oder Veem sauber hinbekommt)
- Möglicherweise negative Auswirkungen des Netzwerks auf die IO Performance
- Bei Ausfall des Storage Servers wäre der gesamte Cluster down, oder bekäme man den auch irgendwie redundant angebunden? iSCSI? irgendwelches ZFS Netzwerk Voodoo?
Habt ihr Anregungen? Ideen? Verbesserungsvorschläge? No Gos?

")