Hi,
i have strange problem with network from some version of 4.3 PVE. Setup is 3 node cluster (G5 + 2x G6 HP servers), openvswitch and dedicated corosync ring0, configured on the same vmbr0 for all nodes and connected to the same switch.
Problematic node:
Rest 2 nodes:
Symptomps:
Updated 1 node ahead of rest 2 marked offline:
Rest nodes:
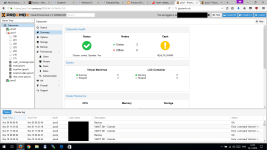
Datacenter Health says: Online 3 (but no Uptime in Nodes). Prox1 is marked with "red X" in the "Server View". Prox1->Summary shows "CPU usage" changing, but graphs are empty. So, every menu/info works without failure even from webinterface from other node.
Problematic node eventually stops responding to snmp check around 11:45. No VMs on prox1, so no info, if connection problem is there too. SNMPd restart didnt helped to resolving monitoring. So, i restarted in this order: corosync, pve-cluster, pve-ha-lrm, pve-ha-crm, pveproxy, pvedaemon.
Still no snmp working, still marked "red X".
Any debug idea? I am not sure, if update rest 2 to having same version, because i dont want getting problems with VMs on prox2 node...
i have strange problem with network from some version of 4.3 PVE. Setup is 3 node cluster (G5 + 2x G6 HP servers), openvswitch and dedicated corosync ring0, configured on the same vmbr0 for all nodes and connected to the same switch.
Code:
Membership information
----------------------
Nodeid Votes Name
1 1 prox0-coro0 (local)
3 1 prox1-coro0
2 1 prox2-coro0
Quorum information
------------------
Date: Wed Nov 30 12:07:05 2016
Quorum provider: corosync_votequorum
Nodes: 3
Node ID: 0x00000001
Ring ID: 1/1552
Quorate: Yes
Votequorum information
----------------------
Expected votes: 3
Highest expected: 3
Total votes: 3
Quorum: 2
Flags: Quorate
Membership information
----------------------
Nodeid Votes Name
0x00000001 1 172.16.0.10 (local)
0x00000003 1 172.16.0.11
0x00000002 1 172.16.0.12Problematic node:
Code:
proxmox-ve: 4.3-72 (running kernel: 4.4.21-1-pve)
pve-manager: 4.3-12 (running version: 4.3-12/6894c9d9)
pve-kernel-4.4.21-1-pve: 4.4.21-71
pve-kernel-4.4.24-1-pve: 4.4.24-72
pve-kernel-4.4.19-1-pve: 4.4.19-66
lvm2: 2.02.116-pve3
corosync-pve: 2.4.0-1
libqb0: 1.0-1
pve-cluster: 4.0-47
qemu-server: 4.0-96
pve-firmware: 1.1-10
libpve-common-perl: 4.0-83
libpve-access-control: 4.0-19
libpve-storage-perl: 4.0-68
pve-libspice-server1: 0.12.8-1
vncterm: 1.2-1
pve-docs: 4.3-17
pve-qemu-kvm: 2.7.0-8
pve-container: 1.0-85
pve-firewall: 2.0-31
pve-ha-manager: 1.0-38
ksm-control-daemon: 1.2-1
glusterfs-client: 3.5.2-2+deb8u2
lxc-pve: 2.0.6-1
lxcfs: 2.0.5-pve1
criu: 1.6.0-1
novnc-pve: 0.5-8
smartmontools: 6.5+svn4324-1~pve80
zfsutils: 0.6.5.8-pve13~bpo80
openvswitch-switch: 2.6.0-2Rest 2 nodes:
Code:
proxmox-ve: 4.3-71 (running kernel: 4.4.21-1-pve)
pve-manager: 4.3-10 (running version: 4.3-10/7230e60f)
pve-kernel-4.4.6-1-pve: 4.4.6-48
pve-kernel-4.4.21-1-pve: 4.4.21-71
pve-kernel-4.4.15-1-pve: 4.4.15-60
pve-kernel-4.4.19-1-pve: 4.4.19-66
lvm2: 2.02.116-pve3
corosync-pve: 2.4.0-1
libqb0: 1.0-1
pve-cluster: 4.0-47
qemu-server: 4.0-94
pve-firmware: 1.1-10
libpve-common-perl: 4.0-80
libpve-access-control: 4.0-19
libpve-storage-perl: 4.0-68
pve-libspice-server1: 0.12.8-1
vncterm: 1.2-1
pve-docs: 4.3-14
pve-qemu-kvm: 2.7.0-8
pve-container: 1.0-81
pve-firewall: 2.0-31
pve-ha-manager: 1.0-35
ksm-control-daemon: 1.2-1
glusterfs-client: 3.5.2-2+deb8u2
lxc-pve: 2.0.5-1
lxcfs: 2.0.4-pve2
criu: 1.6.0-1
novnc-pve: 0.5-8
smartmontools: 6.5+svn4324-1~pve80
zfsutils: 0.6.5.8-pve13~bpo80
openvswitch-switch: 2.5.0-1Symptomps:
Updated 1 node ahead of rest 2 marked offline:
Code:
Nov 29 06:23:00 prox1 corosync[1769]: [TOTEM ] A processor failed, forming new configuration.
Nov 29 06:23:02 prox1 corosync[1769]: [TOTEM ] A new membership (172.16.0.11:1548) was formed. Members left: 1 2
Nov 29 06:23:02 prox1 corosync[1769]: [TOTEM ] Failed to receive the leave message. failed: 1 2
Nov 29 06:23:02 prox1 corosync[1769]: [QUORUM] This node is within the non-primary component and will NOT provide any services.
Nov 29 06:23:02 prox1 corosync[1769]: [QUORUM] Members[1]: 3
Nov 29 06:23:02 prox1 corosync[1769]: [MAIN ] Completed service synchronization, ready to provide service.
Nov 29 06:23:52 prox1 corosync[1769]: [TOTEM ] A new membership (172.16.0.10:1552) was formed. Members joined: 1 2
Nov 29 06:23:52 prox1 corosync[1769]: [QUORUM] This node is within the primary component and will provide service.
Nov 29 06:23:52 prox1 corosync[1769]: [QUORUM] Members[3]: 1 3 2
Nov 29 06:23:52 prox1 corosync[1769]: [MAIN ] Completed service synchronization, ready to provide service.
Nov 30 04:30:06 prox1 corosync[1769]: [TOTEM ] Retransmit List: a2c39
Nov 30 04:30:07 prox1 corosync[1769]: [TOTEM ] Retransmit List: a2c4c
Nov 30 04:30:07 prox1 corosync[1769]: [TOTEM ] Retransmit List: a2c4e
Nov 30 04:30:08 prox1 corosync[1769]: [TOTEM ] Retransmit List: a2c51
Nov 30 04:30:08 prox1 corosync[1769]: [TOTEM ] Retransmit List: a2c52
Nov 30 04:30:10 prox1 corosync[1769]: [TOTEM ] Retransmit List: a2c5bRest nodes:
Code:
Nov 29 06:23:00 prox2 corosync[1766]: [TOTEM ] A processor failed, forming new configuration.
Nov 29 06:23:02 prox2 corosync[1766]: [TOTEM ] A new membership (172.16.0.10:1548) was formed. Members left: 3
Nov 29 06:23:02 prox2 corosync[1766]: [TOTEM ] Failed to receive the leave message. failed: 3
Nov 29 06:23:02 prox2 corosync[1766]: [QUORUM] Members[2]: 1 2
Nov 29 06:23:02 prox2 corosync[1766]: [MAIN ] Completed service synchronization, ready to provide service.
Nov 29 06:23:52 prox2 corosync[1766]: [TOTEM ] A new membership (172.16.0.10:1552) was formed. Members joined: 3
Nov 29 06:23:52 prox2 corosync[1766]: [QUORUM] Members[3]: 1 3 2
Nov 29 06:23:52 prox2 corosync[1766]: [MAIN ] Completed service synchronization, ready to provide service.
Nov 30 03:00:26 prox2 corosync[1766]: [TOTEM ] Retransmit List: 97bd0 97bd1
Code:
Nov 29 06:23:00 prox0 corosync[1415]: [TOTEM ] A processor failed, forming new configuration.
Nov 29 06:23:02 prox0 corosync[1415]: [TOTEM ] A new membership (172.16.0.10:1548) was formed. Members left: 3
Nov 29 06:23:02 prox0 corosync[1415]: [TOTEM ] Failed to receive the leave message. failed: 3
Nov 29 06:23:02 prox0 corosync[1415]: [QUORUM] Members[2]: 1 2
Nov 29 06:23:02 prox0 corosync[1415]: [MAIN ] Completed service synchronization, ready to provide service.
Nov 29 06:23:52 prox0 corosync[1415]: [TOTEM ] A new membership (172.16.0.10:1552) was formed. Members joined: 3
Nov 29 06:23:52 prox0 corosync[1415]: [QUORUM] Members[3]: 1 3 2
Nov 29 06:23:52 prox0 corosync[1415]: [MAIN ] Completed service synchronization, ready to provide service.
Nov 30 04:30:06 prox0 corosync[1415]: [TOTEM ] Retransmit List: a2c39
Nov 30 04:30:06 prox0 corosync[1415]: [TOTEM ] Retransmit List: a2c42
Nov 30 04:30:07 prox0 corosync[1415]: [TOTEM ] Retransmit List: a2c4c
Nov 30 04:30:07 prox0 corosync[1415]: [TOTEM ] Retransmit List: a2c4e
Nov 30 04:30:07 prox0 corosync[1415]: [TOTEM ] Retransmit List: a2c4f
Nov 30 04:30:07 prox0 corosync[1415]: [TOTEM ] Retransmit List: a2c50
Nov 30 04:30:08 prox0 corosync[1415]: [TOTEM ] Retransmit List: a2c51
Nov 30 04:30:08 prox0 corosync[1415]: [TOTEM ] Retransmit List: a2c52
Nov 30 04:30:09 prox0 corosync[1415]: [TOTEM ] Retransmit List: a2c54
Nov 30 04:30:10 prox0 corosync[1415]: [TOTEM ] Retransmit List: a2c5a
Nov 30 04:30:10 prox0 corosync[1415]: [TOTEM ] Retransmit List: a2c5bDatacenter Health says: Online 3 (but no Uptime in Nodes). Prox1 is marked with "red X" in the "Server View". Prox1->Summary shows "CPU usage" changing, but graphs are empty. So, every menu/info works without failure even from webinterface from other node.
Problematic node eventually stops responding to snmp check around 11:45. No VMs on prox1, so no info, if connection problem is there too. SNMPd restart didnt helped to resolving monitoring. So, i restarted in this order: corosync, pve-cluster, pve-ha-lrm, pve-ha-crm, pveproxy, pvedaemon.
Still no snmp working, still marked "red X".
Any debug idea? I am not sure, if update rest 2 to having same version, because i dont want getting problems with VMs on prox2 node...