Hi Everyone,
Appologies, this is going to be a bit rough and hopefully someone can point me to the proper logs for additional information as required. I've learned my lesson not to not try to "Fix" things before reaching out for help so I don't make it worse. Unfortuntely I still have not learned my lesson about not upgrading PVE because I have problems every time.
I wish the GUI had a way to select a couple of upgrades at a time or some way to install less than everything at once, so I have no idea which upgrade may have cause the problems. Ideally I would have done all the package updates separately, before doing the 8.4 related upgrade, but things don't really appear to be broken down that way, other than the two groups upstream/Debian, and Proxmox.
Anyways, this is non-production 3-node cluster, no HA or ceph. It turns on and runs fine, but over the next few hours this node will crash again for the 3rd time since upgrading last night. Actually, it lasted about 10 minutes before crashing as I am typing this.
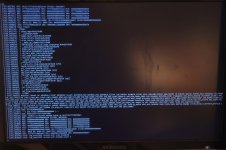
Lots of lines like this, the only difference seems to be the 3 different addresses.
That specific device on 04: is the i211 nic and it is in IOMMU group 15, and so are the other 2 nics (PCIe gigabit, PCIex4 10gbe ethernet ACQ107, and onboard intel). I assume that whole group is the main controller in the cpu, or maybe the northbridge I guess.
Any help or guidance is appreaciated. 2 of the nics are bridged and ahve worked flawlessly until upgrading last night, so I think maybe a driver issue? None of them are using iommu passthrough, they are all directly for this host/node.
And just now the truenas guest has crashed out, connecting to the console looks like a crashed gpu driver. Machine has an old GTX750 that Plex lxc has unpriviledged access to, also running flawless for a couple of weeks before the upgrade. I'm turning off most of the guests and restarting the node and I'll see if it is still online when I get home from work. That may point in a LXC breaking the kernel or something, but my I'm still pretty earlier in my linux troubleshooting journey.
Appologies, this is going to be a bit rough and hopefully someone can point me to the proper logs for additional information as required. I've learned my lesson not to not try to "Fix" things before reaching out for help so I don't make it worse. Unfortuntely I still have not learned my lesson about not upgrading PVE because I have problems every time.
I wish the GUI had a way to select a couple of upgrades at a time or some way to install less than everything at once, so I have no idea which upgrade may have cause the problems. Ideally I would have done all the package updates separately, before doing the 8.4 related upgrade, but things don't really appear to be broken down that way, other than the two groups upstream/Debian, and Proxmox.
Anyways, this is non-production 3-node cluster, no HA or ceph. It turns on and runs fine, but over the next few hours this node will crash again for the 3rd time since upgrading last night. Actually, it lasted about 10 minutes before crashing as I am typing this.
[ 592.660802] igb 0000:04:0: AMD-Vi: Event logged [IO_PAGE_FAULT domain=0x0010 address=0xbe16a0c0 flags=0x0020][ 592.660802] igb 0000:04:0: AMD-Vi: Event logged [IO_PAGE_FAULT domain=0x0010 address=0xbe16a1c0 flags=0x0020][ 592.660802] igb 0000:04:0: AMD-Vi: Event logged [IO_PAGE_FAULT domain=0x0010 address=0xbe16a8c0 flags=0x0020]Lots of lines like this, the only difference seems to be the 3 different addresses.
That specific device on 04: is the i211 nic and it is in IOMMU group 15, and so are the other 2 nics (PCIe gigabit, PCIex4 10gbe ethernet ACQ107, and onboard intel). I assume that whole group is the main controller in the cpu, or maybe the northbridge I guess.
Any help or guidance is appreaciated. 2 of the nics are bridged and ahve worked flawlessly until upgrading last night, so I think maybe a driver issue? None of them are using iommu passthrough, they are all directly for this host/node.
And just now the truenas guest has crashed out, connecting to the console looks like a crashed gpu driver. Machine has an old GTX750 that Plex lxc has unpriviledged access to, also running flawless for a couple of weeks before the upgrade. I'm turning off most of the guests and restarting the node and I'll see if it is still online when I get home from work. That may point in a LXC breaking the kernel or something, but my I'm still pretty earlier in my linux troubleshooting journey.