Hallo Zusammen
Vielleicht kann mir jemand helfen; mein ceph ist tot & ich kann ihn nicht wiederbeleben :-(
Der betroffene Cluster hat
Gestern abend 20:waren plötzlich alle VMs & CTs offline; Blick ins syslog von Node 2 (n02) offenbarte den Grund; mon2 auf n05 -> session lost; mon0 auf n01 ist nicht präsent (wie erwähnt seit > 1 Woche); und auch der Versuch mon1 auf n03 zu benützen schlägt fehl.



Wie man auch sieht, beschwert sich KNET darüber, dass die Verbindung zu host 3 down ist... Ein Blick weiter zurück im Protokoll zeigt, dass die KNET-Beschwerden über mangelnde Verbindung zu n03 schon länger andauern...
Habe alle nodes neu gestartet. Aktueller Status ist:




...und nun die spannende Frage: Kann dieser Ceph von den Toten Auferstehen - und wo/wie könnte ich ansetzen?
lG lucentwolf
Vielleicht kann mir jemand helfen; mein ceph ist tot & ich kann ihn nicht wiederbeleben :-(
Der betroffene Cluster hat
- 7 Knoten
- 2 OSDs je Knoten (1 x HDD, 1 x SSD)
- 4 Pools: cephfs, hdd-only mit erasure, hdd-only mit 3/2, ssd-only mit 3/2
- 3 ceph-mon auf n01 n03 n05 (wobei n01 seit > 1 Woche offline ist -> Hardware Wartung)
- 3 ceph-mgr auf n02 n04 n06
- Netzwerk (je Knoten 2 x 1g und 2 x 10g)
- 1 x 1g Front (1 Switch)
- 1 x 1g cluster (1 switch)
- 2 x 10g (ceph front, ceph back/refill) (beide auf 1 switch)
Gestern abend 20:waren plötzlich alle VMs & CTs offline; Blick ins syslog von Node 2 (n02) offenbarte den Grund; mon2 auf n05 -> session lost; mon0 auf n01 ist nicht präsent (wie erwähnt seit > 1 Woche); und auch der Versuch mon1 auf n03 zu benützen schlägt fehl.
Wie man auch sieht, beschwert sich KNET darüber, dass die Verbindung zu host 3 down ist... Ein Blick weiter zurück im Protokoll zeigt, dass die KNET-Beschwerden über mangelnde Verbindung zu n03 schon länger andauern...
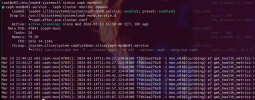
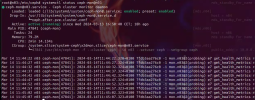
Habe alle nodes neu gestartet. Aktueller Status ist:
- KNET-down-Meldungen kommen keine mehr
- ceph-mon@n03 startet; ceph-mon@n05 startet nicht:
- ceph-mgr startet auf n02 n04 n06 n07; jedoch nicht auf den beiden nodes, auf welchen die ceph-mon laufen (sollten) nämlich n03 und n05

- offenbar AUTH; wobei das keyring-file in /var/lib/ceph/mgr/ceph-n04 fehlt (obgleich 'Permission denied' steht)

- und auf n03: 'No such file...' -> was korrekt ist - es fehlt

...und nun die spannende Frage: Kann dieser Ceph von den Toten Auferstehen - und wo/wie könnte ich ansetzen?
lG lucentwolf




")



")
