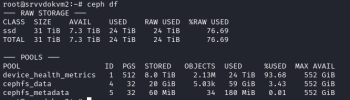
Since the "device_health_metrics" pool is present, you must be on older versions of Ceph & Proxmox VE.
Before you upgrade, create a new pool and move all the disk of the VMs to it. If you check the configuration of the "CephPool01" storage in Datacenter -> Storage, it will most likely show that the "device_health_metrics" pool is used.
It was possible to use it for disk image storage due to not enough safety checks in older versions of Proxmox VE.
Only once you have moved all disk to the new pool, can you consider upgrading.
The reason is that in newer Ceph versions, this pool gets renamed to ".mgr" and will break the disk images in the process!
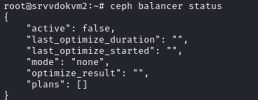
The reason why you see the overall space go down is because some OSDs are quite a bit fuller than others. Check if the balancer is enabled.
It will make sure that OSDs are used more evenly by moving PGs around in cases where the CRUSH algorithm alone is not able to provide a good even distribution of the data across OSDs.
You should be at max on Pacific (v16). The Balancer docs for this version can be found at
https://docs.ceph.com/en/pacific/rados/operations/balancer/