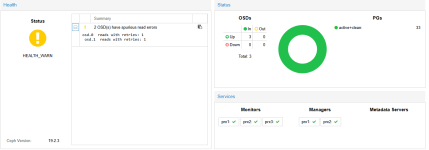
Hi,
ich bin neu bei Proxmox und habe ein 3 Node Clusteraufgebaut und auch einen CEPH Storage Pool eingerichtet. Jeder Node hat local eine SSD Platte. Es lief einige Tage ohne Probleme aber ich habe jetzt schon das zweite mal die o.g. Meldung und der Status geht auf HEALTH_WARN im CEPH. An sich ja wohl kein Problem aber schon etwas komisch wenn das CEPH im WARN bleibt.
Woher kann das kommen? Wie kann ich versuchen das zu verhindern? Oder haben die neuen SSDs hier schon direkt ein HW Problem?
Was ich auch nicht so richtig finden konnte, ist wie den Status acknowleged damit es wieder auf grün geht.
Grüße
Guddi
ich bin neu bei Proxmox und habe ein 3 Node Clusteraufgebaut und auch einen CEPH Storage Pool eingerichtet. Jeder Node hat local eine SSD Platte. Es lief einige Tage ohne Probleme aber ich habe jetzt schon das zweite mal die o.g. Meldung und der Status geht auf HEALTH_WARN im CEPH. An sich ja wohl kein Problem aber schon etwas komisch wenn das CEPH im WARN bleibt.
Code:
2025-12-12T13:59:55.488574+0100 osd.2 (osd.2) 15 : cluster [DBG] 2.c deep-scrub starts
2025-12-12T13:59:57.268973+0100 mgr.prx1 (mgr.925015) 88012 : cluster [DBG] pgmap v88066: 33 pgs: 33 active+clean; 24 GiB data, 68 GiB used, 1.3 TiB / 1.4 TiB avail; 101 KiB/s wr, 4 op/s
2025-12-12T13:59:59.269361+0100 mgr.prx1 (mgr.925015) 88013 : cluster [DBG] pgmap v88067: 33 pgs: 1 active+clean+scrubbing+deep, 32 active+clean; 24 GiB data, 68 GiB used, 1.3 TiB / 1.4 TiB avail; 132 KiB/s wr, 9 op/s
2025-12-12T13:59:59.474179+0100 mon.prx1 (mon.0) 26287 : cluster [WRN] Health check failed: 2 OSD(s) have spurious read errors (BLUESTORE_SPURIOUS_READ_ERRORS)
2025-12-12T14:00:00.000111+0100 mon.prx1 (mon.0) 26288 : cluster [WRN] Health detail: HEALTH_WARN 2 OSD(s) have spurious read errors
2025-12-12T14:00:00.000144+0100 mon.prx1 (mon.0) 26289 : cluster [WRN] [WRN] BLUESTORE_SPURIOUS_READ_ERRORS: 2 OSD(s) have spurious read errors
2025-12-12T14:00:00.000151+0100 mon.prx1 (mon.0) 26290 : cluster [WRN] osd.0 reads with retries: 1
2025-12-12T14:00:00.000162+0100 mon.prx1 (mon.0) 26291 : cluster [WRN] osd.1 reads with retries: 1Woher kann das kommen? Wie kann ich versuchen das zu verhindern? Oder haben die neuen SSDs hier schon direkt ein HW Problem?
Was ich auch nicht so richtig finden konnte, ist wie den Status acknowleged damit es wieder auf grün geht.
Grüße
Guddi