Dear community members!
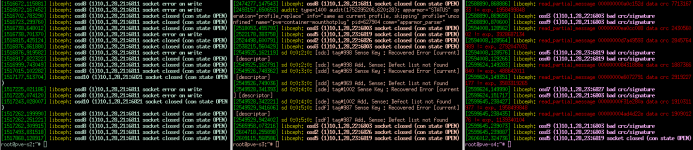
I wonder if I need to worry about ceph messages in dmesg of all three nodes of the cluster:

These are all DL385 Gen10 Servers with SAS SSDs on internal SAS controller in HBA mode (P408i).
It's somehow interesting that pve-s2 does show only "socket error on write" and "socket closed" errors.
s3 and s4 report both crc/signature and red read_partial_message errors.
Here is my system information:
pveversion -v
ceph versions
Ceph backend networking is done with dual 25GbE (LACP trunk):
pve-s2: both backend links on same mellanox connextx-5 nic
pve-s2 & s3: one link on mellanox connextx-5 nic, other on broadcom BCM57414 NetXtreme-E 10Gb/25Gb
While writing this post I notice that one of the key differences is the broadcom nic in servers s3 and s4.
It was initially put there on purpose since we had it available and to minimize the risk of a driver or hardware failure (SPOF).
Attached the huge output of "ethtool -S" for each of the 25GbE interfaces.
I have a strong feeling that the problem is network related but have not yet found the root cause nor a solution.
Thanks for your assistance and guidance!
Best regards,
Bernhard
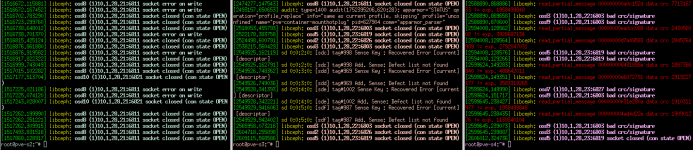
I wonder if I need to worry about ceph messages in dmesg of all three nodes of the cluster:
These are all DL385 Gen10 Servers with SAS SSDs on internal SAS controller in HBA mode (P408i).
It's somehow interesting that pve-s2 does show only "socket error on write" and "socket closed" errors.
s3 and s4 report both crc/signature and red read_partial_message errors.
Here is my system information:
pveversion -v
Code:
proxmox-ve: 8.4.0 (running kernel: 6.8.12-11-pve)
pve-manager: 8.4.1 (running version: 8.4.1/2a5fa54a8503f96d)
proxmox-kernel-helper: 8.1.1
proxmox-kernel-6.8.12-11-pve-signed: 6.8.12-11
proxmox-kernel-6.8: 6.8.12-11
proxmox-kernel-6.8.12-9-pve-signed: 6.8.12-9
ceph: 19.2.1-pve3
ceph-fuse: 19.2.1-pve3
corosync: 3.1.9-pve1
criu: 3.17.1-2+deb12u1
frr-pythontools: 10.2.2-1+pve1
glusterfs-client: 10.3-5
ifupdown2: 3.2.0-1+pmx11
ksm-control-daemon: 1.5-1
libjs-extjs: 7.0.0-5
libknet1: 1.30-pve2
libproxmox-acme-perl: 1.6.0
libproxmox-backup-qemu0: 1.5.1
libproxmox-rs-perl: 0.3.5
libpve-access-control: 8.2.2
libpve-apiclient-perl: 3.3.2
libpve-cluster-api-perl: 8.1.0
libpve-cluster-perl: 8.1.0
libpve-common-perl: 8.3.1
libpve-guest-common-perl: 5.2.2
libpve-http-server-perl: 5.2.2
libpve-network-perl: 0.11.2
libpve-rs-perl: 0.9.4
libpve-storage-perl: 8.3.6
libspice-server1: 0.15.1-1
lvm2: 2.03.16-2
lxc-pve: 6.0.0-1
lxcfs: 6.0.0-pve2
novnc-pve: 1.6.0-2
proxmox-backup-client: 3.4.1-1
proxmox-backup-file-restore: 3.4.1-1
proxmox-firewall: 0.7.1
proxmox-kernel-helper: 8.1.1
proxmox-mail-forward: 0.3.2
proxmox-mini-journalreader: 1.4.0
proxmox-offline-mirror-helper: 0.6.7
proxmox-widget-toolkit: 4.3.11
pve-cluster: 8.1.0
pve-container: 5.2.7
pve-docs: 8.4.0
pve-edk2-firmware: 4.2025.02-3
pve-esxi-import-tools: 0.7.4
pve-firewall: 5.1.2
pve-firmware: 3.15-4
pve-ha-manager: 4.0.7
pve-i18n: 3.4.4
pve-qemu-kvm: 9.2.0-5
pve-xtermjs: 5.5.0-2
qemu-server: 8.3.14
smartmontools: 7.3-pve1
spiceterm: 3.3.0
swtpm: 0.8.0+pve1
vncterm: 1.8.0
zfsutils-linux: 2.2.7-pve2ceph versions
Code:
{
"mon": {
"ceph version 19.2.1 (c783d93f19f71de89042abf6023076899b42259d) squid (stable)": 3
},
"mgr": {
"ceph version 19.2.1 (c783d93f19f71de89042abf6023076899b42259d) squid (stable)": 3
},
"osd": {
"ceph version 19.2.1 (c783d93f19f71de89042abf6023076899b42259d) squid (stable)": 12
},
"mds": {
"ceph version 19.2.1 (c783d93f19f71de89042abf6023076899b42259d) squid (stable)": 3
},
"overall": {
"ceph version 19.2.1 (c783d93f19f71de89042abf6023076899b42259d) squid (stable)": 21
}
}Ceph backend networking is done with dual 25GbE (LACP trunk):
pve-s2: both backend links on same mellanox connextx-5 nic
pve-s2 & s3: one link on mellanox connextx-5 nic, other on broadcom BCM57414 NetXtreme-E 10Gb/25Gb
Code:
auto bond2
iface bond2 inet static
address 10.1.28.22/24
bond-slaves ens10f0np0 ens2f0np0
bond-miimon 100
bond-mode 802.3ad
bond-xmit-hash-policy layer3+4
mtu 9000
#Ceph #1 25GbEWhile writing this post I notice that one of the key differences is the broadcom nic in servers s3 and s4.
It was initially put there on purpose since we had it available and to minimize the risk of a driver or hardware failure (SPOF).
Attached the huge output of "ethtool -S" for each of the 25GbE interfaces.
I have a strong feeling that the problem is network related but have not yet found the root cause nor a solution.
Thanks for your assistance and guidance!
Best regards,
Bernhard

")