Hello guys,
I have a problem which I cannot explain technically by myself.
I have set up a Proxmox VE single Host with two running containers and an additional PBS as VM on other hardware where the Hypervisor should store the backups of both containers every night.
One container has a 20 GB rootfs and additionally a 20 GB mount point.
As I am using a ZFS RAID 1 Proxmox VE setup with 1 TB space, both rootfs and mount point have been created each as a subvolume on the local ZFS pool for virtual machines and LXC’s.
The other container has a 15 GB rootfs only.
Now here is the thing:
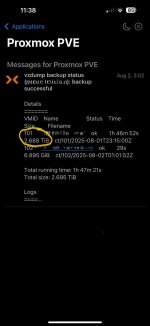
The backup duration of my container with the additional mount point is approximately 2 hours and nearly 3 TB will be crawled (remind that I have only 1 TB of physical disk space overall) in every running backup job.
The duration and crawled data will not reduce after several days as the dedupe functionality of PBS would imply.
The other container is finishing within two minutes after some days and is uploading approximately 65 Megabytes to the PBS datastore every night. This is an expected growing for me because both LXC’s are currently not in production use but system logs will be written.
Both LXC’s are relying on the Debian 12 template from the Proxmox library.
I have attached the web hook notification of the last backup job.
Do you guys have some hints for me where I can start with the troubleshooting?
It is absolutely weird that a LXC of max. 40 GB in size overall would take such a long time for backing up and nearly 3 TB of data will be crawled for it.
Thank you and best,
Daniel
I have a problem which I cannot explain technically by myself.
I have set up a Proxmox VE single Host with two running containers and an additional PBS as VM on other hardware where the Hypervisor should store the backups of both containers every night.
One container has a 20 GB rootfs and additionally a 20 GB mount point.
As I am using a ZFS RAID 1 Proxmox VE setup with 1 TB space, both rootfs and mount point have been created each as a subvolume on the local ZFS pool for virtual machines and LXC’s.
The other container has a 15 GB rootfs only.
Now here is the thing:
The backup duration of my container with the additional mount point is approximately 2 hours and nearly 3 TB will be crawled (remind that I have only 1 TB of physical disk space overall) in every running backup job.
The duration and crawled data will not reduce after several days as the dedupe functionality of PBS would imply.
The other container is finishing within two minutes after some days and is uploading approximately 65 Megabytes to the PBS datastore every night. This is an expected growing for me because both LXC’s are currently not in production use but system logs will be written.
Both LXC’s are relying on the Debian 12 template from the Proxmox library.
I have attached the web hook notification of the last backup job.
Do you guys have some hints for me where I can start with the troubleshooting?
It is absolutely weird that a LXC of max. 40 GB in size overall would take such a long time for backing up and nearly 3 TB of data will be crawled for it.
Thank you and best,
Daniel