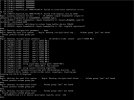
Update completed fine, but RAID became inaccessible on first reboot.
Code:
May 11 14:10:48 DL360-7 pvedaemon[1279]: <root@pam> successful auth for user 'root@pam'
May 11 14:10:50 DL360-7 kernel: [ 95.195448] hpsa 0000:05:00.0: Controller lockup detected: 0xffff0000 after 30
May 11 14:10:50 DL360-7 kernel: [ 95.195460] hpsa 0000:05:00.0: Telling controller to do a CHKPT
May 11 14:10:50 DL360-7 kernel: [ 95.195510] hpsa 0000:05:00.0: controller lockup detected: LUN:0000004000000000 CDB:01040000000000000000000000000000
May 11 14:10:50 DL360-7 kernel: [ 95.195518] hpsa 0000:05:00.0: Controller lockup detected during reset wait
May 11 14:10:50 DL360-7 kernel: [ 95.195523] hpsa 0000:05:00.0: scsi 2:1:0:0: reset logical failed Direct-Access HP LOGICAL VOLUME RAID-5 SSDSmartPathCap- En- Exp=1
May 11 14:10:50 DL360-7 kernel: [ 95.195537] sd 2:1:0:0: Device offlined - not ready after error recovery
May 11 14:10:50 DL360-7 kernel: [ 95.195541] sd 2:1:0:0: Device offlined - not ready after error recovery
May 11 14:10:50 DL360-7 kernel: [ 95.195544] sd 2:1:0:0: Device offlined - not ready after error recovery
May 11 14:10:50 DL360-7 kernel: [ 95.195549] sd 2:1:0:0: Device offlined - not ready after error recovery
May 11 14:10:50 DL360-7 kernel: [ 95.195549] hpsa 0000:05:00.0: failed 13 commands in fail_all
May 11 14:10:50 DL360-7 kernel: [ 95.195550] sd 2:1:0:0: Device offlined - not ready after error recovery
May 11 14:10:50 DL360-7 kernel: [ 95.195552] sd 2:1:0:0: Device offlined - not ready after error recovery
May 11 14:10:50 DL360-7 kernel: [ 95.195554] sd 2:1:0:0: Device offlined - not ready after error recovery
May 11 14:10:50 DL360-7 kernel: [ 95.195555] sd 2:1:0:0: Device offlined - not ready after error recovery
May 11 14:10:50 DL360-7 kernel: [ 95.195557] sd 2:1:0:0: Device offlined - not ready after error recovery
May 11 14:10:50 DL360-7 kernel: [ 95.195558] sd 2:1:0:0: Device offlined - not ready after error recovery
May 11 14:10:50 DL360-7 kernel: [ 95.195560] sd 2:1:0:0: Device offlined - not ready after error recovery
May 11 14:10:50 DL360-7 kernel: [ 95.195561] sd 2:1:0:0: Device offlined - not ready after error recovery
May 11 14:10:50 DL360-7 kernel: [ 95.195575] sd 2:1:0:0: [sdb] tag#967 FAILED Result: hostbyte=DID_NO_CONNECT driverbyte=DRIVER_OK cmd_age=74s
May 11 14:10:50 DL360-7 kernel: [ 95.195579] sd 2:1:0:0: [sdb] tag#967 CDB: Read(10) 28 00 00 00 00 00 00 01 00 00
May 11 14:10:50 DL360-7 kernel: [ 95.195580] blk_update_request: I/O error, dev sdb, sector 0 op 0x0:(READ) flags 0x0 phys_seg 3 prio class 0
May 11 14:10:50 DL360-7 kernel: [ 95.195887] sd 2:1:0:0: [sdb] tag#781 FAILED Result: hostbyte=DID_NO_CONNECT driverbyte=DRIVER_OK cmd_age=75s
May 11 14:10:50 DL360-7 kernel: [ 95.195890] sd 2:1:0:0: [sdb] tag#781 CDB: Write(10) 2a 00 00 01 29 38 00 00 08 00
May 11 14:10:50 DL360-7 kernel: [ 95.195891] blk_update_request: I/O error, dev sdb, sector 76088 op 0x1:(WRITE) flags 0x3800 phys_seg 1 prio class 0
May 11 14:10:50 DL360-7 kernel: [ 95.196193] Buffer I/O error on dev dm-8, logical block 9255, lost sync page write
May 11 14:10:50 DL360-7 kernel: [ 95.196420] sd 2:1:0:0: [sdb] tag#880 FAILED Result: hostbyte=DID_NO_CONNECT driverbyte=DRIVER_OK cmd_age=75s
May 11 14:10:50 DL360-7 kernel: [ 95.196423] sd 2:1:0:0: [sdb] tag#880 CDB: Read(10) 28 00 00 00 28 08 00 00 08 00
May 11 14:10:50 DL360-7 kernel: [ 95.196424] blk_update_request: I/O error, dev sdb, sector 10248 op 0x0:(READ) flags 0x83700 phys_seg 1 prio class 0
May 11 14:10:50 DL360-7 kernel: [ 95.196484] EXT4-fs error (device dm-8): kmmpd:179: comm kmmpd-dm-8: Error writing to MMP block
May 11 14:10:50 DL360-7 kernel: [ 95.196504] sd 2:1:0:0: rejecting I/O to offline device
May 11 14:10:50 DL360-7 kernel: [ 95.196508] blk_update_request: I/O error, dev sdb, sector 8652800 op 0x1:(WRITE) flags 0x800 phys_seg 1 prio class 0
May 11 14:10:50 DL360-7 kernel: [ 95.196513] Buffer I/O error on dev dm-8, logical block 1081344, lost sync page write
May 11 14:10:50 DL360-7 kernel: [ 95.196521] JBD2: Error -5 detected when updating journal superblock for dm-8-8.
May 11 14:10:50 DL360-7 kernel: [ 95.196523] Aborting journal on device dm-8-8.
May 11 14:10:50 DL360-7 kernel: [ 95.196545] blk_update_request: I/O error, dev sdb, sector 8652800 op 0x1:(WRITE) flags 0x800 phys_seg 1 prio class 0
May 11 14:10:50 DL360-7 kernel: [ 95.196549] Buffer I/O error on dev dm-8, logical block 1081344, lost sync page write
May 11 14:10:50 DL360-7 kernel: [ 95.196553] JBD2: Error -5 detected when updating journal superblock for dm-8-8.
May 11 14:10:50 DL360-7 kernel: [ 95.196729] sd 2:1:0:0: [sdb] tag#881 FAILED Result: hostbyte=DID_NO_CONNECT driverbyte=DRIVER_OK cmd_age=75s
May 11 14:10:50 DL360-7 kernel: [ 95.196993] blk_update_request: I/O error, dev sdb, sector 76088 op 0x1:(WRITE) flags 0x3800 phys_seg 1 prio class 0
May 11 14:10:50 DL360-7 kernel: [ 95.197121] sd 2:1:0:0: [sdb] tag#881 CDB: Read(10) 28 00 00 40 08 08 00 00 20 00
May 11 14:10:50 DL360-7 kernel: [ 95.197420] Buffer I/O error on dev dm-8, logical block 9255, lost sync page write
May 11 14:10:50 DL360-7 kernel: [ 95.197639] blk_update_request: I/O error, dev sdb, sector 4196360 op 0x0:(READ) flags 0x83700 phys_seg 4 prio class 0
May 11 14:10:50 DL360-7 kernel: [ 95.197876] blk_update_request: I/O error, dev sdb, sector 2048 op 0x1:(WRITE) flags 0x3800 phys_seg 1 prio class 0
May 11 14:10:50 DL360-7 kernel: [ 95.197982] sd 2:1:0:0: [sdb] tag#882 FAILED Result: hostbyte=DID_NO_CONNECT driverbyte=DRIVER_OK cmd_age=75s
May 11 14:10:50 DL360-7 kernel: [ 95.198273] Buffer I/O error on dev dm-8, logical block 0, lost sync page write
May 11 14:10:50 DL360-7 kernel: [ 95.198493] sd 2:1:0:0: [sdb] tag#882 CDB: Read(10) 28 00 00 40 08 60 00 00 18 00
May 11 14:10:50 DL360-7 kernel: [ 95.198704] EXT4-fs (dm-8): I/O error while writing superblock
May 11 14:10:50 DL360-7 kernel: [ 95.198997] blk_update_request: I/O error, dev sdb, sector 4196448 op 0x0:(READ) flags 0x83700 phys_seg 3 prio class 0
May 11 14:10:51 DL360-7 kernel: [ 95.200497] sd 2:1:0:0: [sdb] tag#883 FAILED Result: hostbyte=DID_NO_CONNECT driverbyte=DRIVER_OK cmd_age=75s
May 11 14:10:51 DL360-7 kernel: [ 95.200499] sd 2:1:0:0: [sdb] tag#883 CDB: Read(10) 28 00 00 80 08 00 00 00 10 00
May 11 14:10:51 DL360-7 kernel: [ 95.200501] blk_update_request: I/O error, dev sdb, sector 8390656 op 0x0:(READ) flags 0x83700 phys_seg 2 prio class 0
May 11 14:10:51 DL360-7 kernel: [ 95.209562] sd 2:1:0:0: [sdb] tag#884 FAILED Result: hostbyte=DID_NO_CONNECT driverbyte=DRIVER_OK cmd_age=75s
May 11 14:10:51 DL360-7 kernel: [ 95.209565] sd 2:1:0:0: [sdb] tag#884 CDB: Read(10) 28 00 00 80 08 18 00 00 60 00
May 11 14:10:51 DL360-7 kernel: [ 95.209571] sd 2:1:0:0: [sdb] tag#885 FAILED Result: hostbyte=DID_NO_CONNECT driverbyte=DRIVER_OK cmd_age=75s
May 11 14:10:51 DL360-7 kernel: [ 95.209574] sd 2:1:0:0: [sdb] tag#885 CDB: Read(10) 28 00 00 c0 08 00 00 00 18 00
May 11 14:10:51 DL360-7 kernel: [ 95.209579] sd 2:1:0:0: [sdb] tag#886 FAILED Result: hostbyte=DID_NO_CONNECT driverbyte=DRIVER_OK cmd_age=75s
May 11 14:10:51 DL360-7 kernel: [ 95.209581] sd 2:1:0:0: [sdb] tag#886 CDB: Read(10) 28 00 00 c0 08 20 00 00 10 00
May 11 14:10:51 DL360-7 kernel: [ 95.209586] sd 2:1:0:0: [sdb] tag#887 FAILED Result: hostbyte=DID_NO_CONNECT driverbyte=DRIVER_OK cmd_age=75s
May 11 14:10:51 DL360-7 kernel: [ 95.209589] sd 2:1:0:0: [sdb] tag#887 CDB: Read(10) 28 00 00 c0 08 38 00 00 18 00
May 11 14:10:51 DL360-7 kernel: [ 95.209612] EXT4-fs error (device dm-8): __ext4_find_entry:1612: inode #270714: comm systemd: reading directory lblock 0
May 11 14:10:51 DL360-7 kernel: [ 95.209691] EXT4-fs error (device dm-8): ext4_wait_block_bitmap:531: comm ext4lazyinit: Cannot read block bitmap - block_group = 63, block_bitmap = 1572879
May 11 14:10:51 DL360-7 kernel: [ 95.219413] Buffer I/O error on dev dm-8, logical block 0, lost sync page write
May 11 14:10:51 DL360-7 kernel: [ 95.246873] EXT4-fs (dm-8): I/O error while writing superblock
May 11 14:10:51 DL360-7 kernel: [ 95.256218] Buffer I/O error on dev dm-8, logical block 0, lost sync page write
May 11 14:10:51 DL360-7 kernel: [ 95.265682] EXT4-fs (dm-8): I/O error while writing superblock
May 11 14:10:51 DL360-7 kernel: [ 95.316526] fwbr103i0: port 2(veth103i0) entered disabled state
May 11 14:10:51 DL360-7 kernel: [ 95.316634] device veth103i0 left promiscuous mode
May 11 14:10:51 DL360-7 kernel: [ 95.316639] fwbr103i0: port 2(veth103i0) entered disabled state
May 11 14:10:51 DL360-7 kernel: [ 95.811644] audit: type=1400 audit(1652271051.599:21): apparmor="STATUS" operation="profile_remove" profile="/usr/bin/lxc-start" name="lxc-103_</var/lib/lxc>" pid=1821 comm="apparmor_parser"
May 11 14:10:51 DL360-7 kernel: [ 95.840186] EXT4-fs error (device dm-8): ext4_journal_check_start:83: comm lxc-start: Detected aborted journal
May 11 14:10:51 DL360-7 kernel: [ 95.850094] Buffer I/O error on dev dm-8, logical block 0, lost sync page write
May 11 14:10:51 DL360-7 kernel: [ 95.859939] EXT4-fs (dm-8): I/O error while writing superblock
May 11 14:10:51 DL360-7 kernel: [ 95.869691] EXT4-fs (dm-8): Remounting filesystem read-only
May 11 14:10:51 DL360-7 pvestatd[1251]: unable to get PID for CT 103 (not running?)
May 11 14:10:51 DL360-7 pvestatd[1251]: status update time (77.484 seconds)
May 11 14:10:52 DL360-7 kernel: [ 97.166754] Buffer I/O error on dev dm-8, logical block 9255, lost sync page write
May 11 14:10:53 DL360-7 kernel: [ 97.256338] fwbr103i0: port 1(fwln103i0) entered disabled state
May 11 14:10:53 DL360-7 kernel: [ 97.256461] vmbr0: port 2(fwpr103p0) entered disabled state
May 11 14:10:53 DL360-7 kernel: [ 97.257012] device fwln103i0 left promiscuous mode
May 11 14:10:53 DL360-7 kernel: [ 97.257020] fwbr103i0: port 1(fwln103i0) entered disabled state
May 11 14:10:53 DL360-7 kernel: [ 97.275037] device fwpr103p0 left promiscuous mode
May 11 14:10:53 DL360-7 kernel: [ 97.275040] vmbr0: port 2(fwpr103p0) entered disabled state
Last edited: