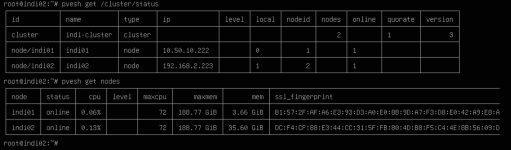
I recently did a network upgrade for my office. We installed new switches and wanted to consolidate and re-ip to a 10.50.x.x. from a 192.168.x.x numbered IPv4 network. Everything appeared to go fine up until we got the two node development proxmox cluster. We changed the IPs fine, the cluster we had some tweaking to do but ultimately it appeared to be working fine. Then we did a pve cluster status and it shows node2 is reporting the old IP, even though the cluster nodes all report the correct 10.50.x.x IPs.
What is also weird and we can't find a resolution for it so far is when we use the UI to open a shell on node 2 ssh complains there is no route and details the old IP address not the new one. For the life of us we can't find any remaining fragments of text in any config files or DNS cache or anything that would retain this information but for some reason SSH is stuck on the old IP.
I've attached two images the first showing the cluster status, the second showing the ssh banner when we try to open node 2's shell from node 1.
We are running 9.2.3 and performed all upgrades prior to changing the IP's, so we are as up to date as possible, as of the writing of this thread.
What is also weird and we can't find a resolution for it so far is when we use the UI to open a shell on node 2 ssh complains there is no route and details the old IP address not the new one. For the life of us we can't find any remaining fragments of text in any config files or DNS cache or anything that would retain this information but for some reason SSH is stuck on the old IP.
I've attached two images the first showing the cluster status, the second showing the ssh banner when we try to open node 2's shell from node 1.
We are running 9.2.3 and performed all upgrades prior to changing the IP's, so we are as up to date as possible, as of the writing of this thread.