I discovered today that one of my nodes was off. I don't currently have physical access since I'm at work so it could very well be some kind of hardware failure, but I remote powered on another node that had been turned off to save power (only have one that has IPMI the others don't), since I wanted to regain redundancy. At that point I lost complete access to my network. It's like the whole cluster completely failed. I was in the dark for about an hour but kept trying to VPN in until I was successful. Thankfully it did recover. I now notice that another node is offline. It seems like a weird coincidence that I get 2 nodes die like this. Is there some sort of log or something I can check to see what happened and is there a mechanism that could cause a node to shutdown? Just seems weird to lose 2 nodes in the same day.
Is there a mechanism that could cause a node to shutdown?
- Thread starter Red Squirrel
- Start date
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
So one of the nodes is actually online, in the sense that I can SSH to it, but it shows up as offline in the cluster. What would cause this? I rebooted it but it still shows offline. When I do pvecm status it shows quorum is blocked. Is there a way to find out why?
I ended up removing the node from the cluster entirely as it was acting weird, like tying to start VMs that are already started on the other nodes. But now it still shows up in the cluster even though pvecm nodes does no longer list it. I ended up shutting it down to prevent corruption because it was running the same VMs twice. I just want to rip it out of the cluster completely and reinstall the OS and rejoin it.
Also the cluster as a whole seems to be very unstable right now, it's like if my VMs are constantly dropping in and out. i keep loosing connection to everything. What a mess.
Also the cluster as a whole seems to be very unstable right now, it's like if my VMs are constantly dropping in and out. i keep loosing connection to everything. What a mess.
Yeah whole cluster is finished. Don't know what to do. VMs are running but it's like the CPU keeps locking on and off on the entire cluster. Performance is complete garbage, can't do anything on any of the VMs. Keep losing connection to the web interface, keep having to hit refresh, SSH connections to servers drop out etc. My whole infrastructure is basically unusable. What can I check to see what's going on?
Im curious, do you know the basic requirements for a cluster to operate normally? How does your cluster look like. Please provide basic information about your whole topology. And please dont reply-reply-reply to your own topic, you can just edit your original post.

He said it doesnt. But first of all we need some basic information about that cluster overallDoes it have a quorum? If not the nodes will reboot.

The cluster itself has quorum but the 4th node did not. it's a 4 node cluster, I set one of the nodes to have 2 votes (this one never went down) as setting up qdevice looks quite involved from what I read, and I plan to add a 5th node eventually so didn't want to go through all that work for something temporary. I should be able to lose at least 1 node, or 2 if it's not the one with 2 votes, at least that's my understanding? Still not sure why the nodes would have shut down though because the cluster did have quorum at that point even with the one node that was off on purpose for over a month. Turning it back on seems to be what triggered more chaos and the 4th node to drop out.
Now I'm down to 3 nodes because the 4th node was acting strange so I removed it, but now the whole cluster is acting up, it basically drops in and out. I will lose connection to web interface, VMs etc then regain it, it's maybe in 30 second intervals. When I do manage to get the web interface it does show I have quorum but the 4th node also still shows up despite me removing it with pvecm delnode.
Now I'm down to 3 nodes because the 4th node was acting strange so I removed it, but now the whole cluster is acting up, it basically drops in and out. I will lose connection to web interface, VMs etc then regain it, it's maybe in 30 second intervals. When I do manage to get the web interface it does show I have quorum but the 4th node also still shows up despite me removing it with pvecm delnode.
Again, we need information about your cluster.
pvecm statuspvecm nodescat /etc/corosync/corosync.confcorosync-cfgtool -s (on all nodes)journalctl -xeu pve-cluster.service
it's a very slow process since SSH keeps locking up but here's the output of those commands:
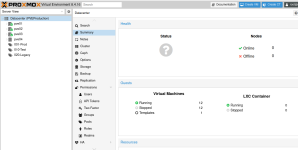
And here's screenshot of web interface to show the 4th node is sitll showing up. Navigating it is extremely slow and keeps timing out. Doing anything on my infrastructure is same thing, trying to SSH to any vm or the PVE nodes etc. it's like everything is just grinding to a halt intermittently.
Edit: Just realize that PVE04 is still running despite me doing a shutdown. It keeps booting back up and starting up all the VMs that are already running on the other nodes. Ended up having to rm -rf the boot partition and then had to do systemctl poweroff --force --force since normal shutdown no longer worked. This seems to have forced it to stay off. I will need to reinstall the OS anyway since it still thinks it's part of the cluster.
Everything seems more stable now... but still early to tell. I'm kind of worried about what happens if I reboot one of the VMs that was double running though... I fear there may be disk corruption. I do have a few with corruption that no longer boot up but the ones already running seem stable. Anything I can do to ensure they won't all corrupt next time they get rebooted? There's only one VM that is locked up with a read only file system the other ones appear to be running fine now...
The 4th node is still showing up in the list too, how do I get rid of that?
Edit2: Looks like the corruption is very bad. Any VM I reboot does not come back up gracefully and ends up with read only FS. What a freaking mess. The instability has also returned where everything locks up. Trying to restore a backup but I lost connection to everything so not sure if it started.
Code:
root@pve02:~# pvecm status
Cluster information
-------------------
Name: PVEProduction
Config Version: 11
Transport: knet
Secure auth: on
Quorum information
------------------
Date: Fri Feb 6 22:48:27 2026
Quorum provider: corosync_votequorum
Nodes: 3
Node ID: 0x00000003
Ring ID: 1.861e
Quorate: Yes
Votequorum information
----------------------
Expected votes: 4
Highest expected: 4
Total votes: 4
Quorum: 3
Flags: Quorate
Membership information
----------------------
Nodeid Votes Name
0x00000001 1 10.1.1.31
0x00000003 2 10.1.1.32 (local)
0x00000004 1 10.1.1.33
root@pve02:~#
root@pve02:~#
root@pve02:~#
root@pve02:~# pvecm nodes
Membership information
----------------------
Nodeid Votes Name
1 1 pve01
3 2 pve02 (local)
4 1 pve03
root@pve02:~#
root@pve02:~#
root@pve02:~# cat /etc/corosync/corosync.conf
logging {
debug: off
to_syslog: yes
}
nodelist {
node {
name: pve01
nodeid: 1
quorum_votes: 1
ring0_addr: 10.1.1.31
}
node {
name: pve02
nodeid: 3
quorum_votes: 2
ring0_addr: 10.1.1.32
}
node {
name: pve03
nodeid: 4
quorum_votes: 1
ring0_addr: 10.1.1.33
}
}
quorum {
provider: corosync_votequorum
}
totem {
cluster_name: PVEProduction
config_version: 11
interface {
linknumber: 0
}
ip_version: ipv4-6
link_mode: passive
secauth: on
version: 2
}
root@pve02:~#
root@pve02:~#
root@pve02:~#
root@pve02:~# journalctl -xeu pve-cluster.service
Feb 06 22:43:34 pve02 pmxcfs[919]: [status] notice: update cluster info (cluste>
Feb 06 22:43:34 pve02 pmxcfs[919]: [status] notice: node has quorum
Feb 06 22:43:34 pve02 pmxcfs[919]: [dcdb] notice: members: 1/874, 3/919, 4/930
Feb 06 22:43:34 pve02 pmxcfs[919]: [dcdb] notice: starting data syncronisation
Feb 06 22:43:34 pve02 pmxcfs[919]: [dcdb] notice: received sync request (epoch >
Feb 06 22:43:34 pve02 pmxcfs[919]: [status] notice: members: 1/874, 3/919, 4/930
Feb 06 22:43:34 pve02 pmxcfs[919]: [status] notice: starting data syncronisation
Feb 06 22:43:34 pve02 pmxcfs[919]: [status] notice: received sync request (epoc>
Feb 06 22:43:34 pve02 pmxcfs[919]: [dcdb] notice: received all states
Feb 06 22:43:34 pve02 pmxcfs[919]: [dcdb] notice: leader is 1/874
Feb 06 22:43:34 pve02 pmxcfs[919]: [dcdb] notice: synced members: 1/874, 4/930
Feb 06 22:43:34 pve02 pmxcfs[919]: [dcdb] notice: waiting for updates from lead>
Feb 06 22:43:34 pve02 pmxcfs[919]: [status] notice: received all states
Feb 06 22:43:34 pve02 pmxcfs[919]: [status] notice: all data is up to date
Feb 06 22:43:34 pve02 pmxcfs[919]: [dcdb] notice: update complete - trying to c>
Feb 06 22:43:34 pve02 pmxcfs[919]: [dcdb] notice: all data is up to date
Feb 06 22:47:52 pve02 pmxcfs[919]: [status] notice: received log
Feb 06 22:47:52 pve02 pmxcfs[919]: [status] notice: received log
Feb 06 22:47:52 pve02 pmxcfs[919]: [status] notice: received log
Feb 06 22:47:52 pve02 pmxcfs[919]: [status] notice: received log
Feb 06 22:47:54 pve02 pmxcfs[919]: [status] notice: received log
Feb 06 22:48:10 pve02 pmxcfs[919]: [status] notice: received log
Feb 06 22:48:22 pve02 pmxcfs[919]: [status] notice: received log
root@pve02:~#
root@pve01:~# corosync-cfgtool -s
Local node ID 1, transport knet
LINK ID 0 udp
addr = 10.1.1.31
status:
nodeid: 1: localhost
nodeid: 3: connected
nodeid: 4: connected
root@pve02:~# corosync-cfgtool -s
Local node ID 3, transport knet
LINK ID 0 udp
addr = 10.1.1.32
status:
nodeid: 1: connected
nodeid: 3: localhost
nodeid: 4: connected
root@pve03:~# corosync-cfgtool -s
Local node ID 4, transport knet
LINK ID 0 udp
addr = 10.1.1.33
status:
nodeid: 1: connected
nodeid: 3: connected
nodeid: 4: localhostAnd here's screenshot of web interface to show the 4th node is sitll showing up. Navigating it is extremely slow and keeps timing out. Doing anything on my infrastructure is same thing, trying to SSH to any vm or the PVE nodes etc. it's like everything is just grinding to a halt intermittently.
Edit: Just realize that PVE04 is still running despite me doing a shutdown. It keeps booting back up and starting up all the VMs that are already running on the other nodes. Ended up having to rm -rf the boot partition and then had to do systemctl poweroff --force --force since normal shutdown no longer worked. This seems to have forced it to stay off. I will need to reinstall the OS anyway since it still thinks it's part of the cluster.
Everything seems more stable now... but still early to tell. I'm kind of worried about what happens if I reboot one of the VMs that was double running though... I fear there may be disk corruption. I do have a few with corruption that no longer boot up but the ones already running seem stable. Anything I can do to ensure they won't all corrupt next time they get rebooted? There's only one VM that is locked up with a read only file system the other ones appear to be running fine now...
The 4th node is still showing up in the list too, how do I get rid of that?
Edit2: Looks like the corruption is very bad. Any VM I reboot does not come back up gracefully and ends up with read only FS. What a freaking mess. The instability has also returned where everything locks up. Trying to restore a backup but I lost connection to everything so not sure if it started.
Attachments
Last edited:
You didnt even notice that a node rebooted and rejoined your cluster (which after you deleted it should NEVER happen because this can ruin your cluster). IMHO there is more broken then i can see as of now. You could try to remove the node from pve directly now via removing
Other then that would require node restarts or pve-cluster services restarts to check if that helps, also way bigger logs for the cluster services are needed.
If feel at this point and based on what you did so far (and probably did without communicating it here) its save to say that i'd advise you to rebuild your cluster.
/etc/pve/nodes/<nodename>Other then that would require node restarts or pve-cluster services restarts to check if that helps, also way bigger logs for the cluster services are needed.
If feel at this point and based on what you did so far (and probably did without communicating it here) its save to say that i'd advise you to rebuild your cluster.
Last edited:
I am currently in the process of doing that. Most of my VMs got corrupted in this incident so need to rebuild them all, some from backups, some I am able to repair. It's a pain. Still have no idea why this happened but from what I've been told on another forum it sounds like HA does NOT do what I thought it did, and that you really need enterprise grade hardware for it and tons of redundancy at network and server level and a very specialized setup. But at that point you have so much redundancy anyway that you don't even need HA... so it seems counter intuitive. So I will be making my next cluster non HA in hopes that whatever happened does not happen again. And I guess I should also avoid setting VMs to start automatically at startup as that may have been part of my issue. When that node went rogue it would not have started all the VMs at least. That node is out of the picture now and I even pulled the power cord when I got home to make sure it doesn't somehow try to start again but it still shows up in the GUI so I do need to rebuild the cluster itself once I'm done fixing all my VMs so I can get rid of it. Down to 3 nodes now and will stay that way until I add a 5th one.
I have not updated to latest PVE version yet so I will probably do that at the same time, I will update one node at a time via clean install.
Also going to avoid even number of nodes, I knew it was not recommended but did not realize it would cause THIS. I figured the worse case scenario is that losing 2 nodes means you don't get HA and the VMs don't come back, not that it trashes the entire cluster.
Now I know where the word clusterfuck comes from, this is more or less what I'm dealing with lol.
I have not updated to latest PVE version yet so I will probably do that at the same time, I will update one node at a time via clean install.
Also going to avoid even number of nodes, I knew it was not recommended but did not realize it would cause THIS. I figured the worse case scenario is that losing 2 nodes means you don't get HA and the VMs don't come back, not that it trashes the entire cluster.
Now I know where the word clusterfuck comes from, this is more or less what I'm dealing with lol.
You can lose 2 nodes but the cluster does not quorate anymore and thus VMs "stand still" because noone "knows" if whats happening is what is supposed to happen in the cluster ") Thats the reason there is a quorum in the first place, so that nothing "bad" happens at all when stuff like that happens.
Thats the reason there is a quorum in the first place, so that nothing "bad" happens at all when stuff like that happens.
Thats the reason there is a quorum in the first place, so that nothing "bad" happens at all when stuff like that happens.That's what I figured but is not what happened here. Had a node already off, lost another for an unknown reason, booted back the node that I had previously shut down, another node went down, then when I turned on the node that originally went down for an unknown reason another node went rogue and started up VMs already running on the active nodes. Or at least something like that. I kinda lost track of all the events but it was something to that extent. It did start with one node being found to be in off state for an unknown reason which is what originally prompted me to ask if there was a process built in that would cause that but then things spiraled fast when I tried to intervene. It seems that in this process I ended up with split brain for some reason. Wonder if having a node turned off for extended time was maybe a cause? I guess that's not a good idea. Just did not expect it to be destructive.
just glad my backups work... because I don't test them as much as I should, and now I'm really testing them.
Edit:
Looks like I have everything restored now. The nightmare is mostly over.
Also managed to get rid of that rogue node from the GUI. There was one VM config still in the folder and I manually moved it over to one of the other 3 nodes and it vanished. So it seems everything should be working proper now. I will keep it a 3 node cluster for now and wipe the 4th node to make sure I don't accidentally put it on my network and it does weird stuff again. I've set all HA to ignore on all my VMs and plan to no longer use HA, I'm not 100% on if it was the cause, but I suspect it, so want to rule it out at least.
just glad my backups work... because I don't test them as much as I should, and now I'm really testing them.
Edit:
Looks like I have everything restored now. The nightmare is mostly over.
Also managed to get rid of that rogue node from the GUI. There was one VM config still in the folder and I manually moved it over to one of the other 3 nodes and it vanished. So it seems everything should be working proper now. I will keep it a 3 node cluster for now and wipe the 4th node to make sure I don't accidentally put it on my network and it does weird stuff again. I've set all HA to ignore on all my VMs and plan to no longer use HA, I'm not 100% on if it was the cause, but I suspect it, so want to rule it out at least.
Last edited: