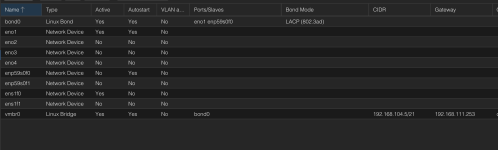
Need help finding and fixing root cause. Below are some details of my finding so far. The cluster is setup with one bond per node and everything is going though it. There are differnt Vlans but I believe its all essentially going though the same physical bond. Internal ceph is running on 6 nodes in the cluster. Corosync is also communicating on this one single link. All servers in the cluster do have at least 4 physical NICs. I have been coming across running corosync on its own physical NIC quite a lot. Could this be it? us running it on single bond per server causes the entire cluster to restart? I have attached a screen shot of how network on each node is setup on proxmox side.
Here are the current Totem settings: can changing any of these values help? or should these be not tinkered with in production?
Bunch of logs like this in corosync syslog on a few nodes: below is one example.
Here are the current Totem settings: can changing any of these values help? or should these be not tinkered with in production?
Code:
runtime.config.totem.block_unlisted_ips (u32) = 1
runtime.config.totem.cancel_token_hold_on_retransmit (u32) = 0
runtime.config.totem.consensus (u32) = 32460
runtime.config.totem.downcheck (u32) = 1000
runtime.config.totem.fail_recv_const (u32) = 2500
runtime.config.totem.heartbeat_failures_allowed (u32) = 0
runtime.config.totem.hold (u32) = 5142
runtime.config.totem.interface.0.knet_ping_interval (u32) = 6762
runtime.config.totem.interface.0.knet_ping_timeout (u32) = 13525
runtime.config.totem.join (u32) = 50
runtime.config.totem.knet_compression_level (i32) = 0
runtime.config.totem.knet_compression_model (str) = none
runtime.config.totem.knet_compression_threshold (u32) = 0
runtime.config.totem.knet_mtu (u32) = 0
runtime.config.totem.knet_pmtud_interval (u32) = 30
runtime.config.totem.max_messages (u32) = 17
runtime.config.totem.max_network_delay (u32) = 50
runtime.config.totem.merge (u32) = 200
runtime.config.totem.miss_count_const (u32) = 5
runtime.config.totem.send_join (u32) = 0
runtime.config.totem.seqno_unchanged_const (u32) = 30
runtime.config.totem.token (u32) = 27050
runtime.config.totem.token_retransmit (u32) = 6440
runtime.config.totem.token_retransmits_before_loss_const (u32) = 4
runtime.config.totem.token_warning (u32) = 75
runtime.config.totem.window_size (u32) = 50
totem.cluster_name (str) = proxmox-prodBunch of logs like this in corosync syslog on a few nodes: below is one example.
Code:
Dec 10 22:48:50 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 19e6f7
Dec 10 23:10:10 proxmox-prod03.sgdctroy.net corosync[3941]: [KNET ] link: host: 9 link: 0 is down
Dec 10 23:10:10 proxmox-prod03.sgdctroy.net corosync[3941]: [KNET ] host: host: 9 (passive) best link: 0 (pri: 1)
Dec 10 23:10:10 proxmox-prod03.sgdctroy.net corosync[3941]: [KNET ] host: host: 9 has no active links
Dec 10 23:10:11 proxmox-prod03.sgdctroy.net corosync[3941]: [KNET ] link: Resetting MTU for link 0 because host 9 joined
Dec 10 23:10:11 proxmox-prod03.sgdctroy.net corosync[3941]: [KNET ] host: host: 9 (passive) best link: 0 (pri: 1)
Dec 10 23:10:11 proxmox-prod03.sgdctroy.net corosync[3941]: [KNET ] pmtud: Global data MTU changed to: 1397
Dec 10 23:13:30 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 1baf4c
Dec 10 23:21:43 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 1c4b06
Dec 11 00:06:17 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 1f7228
Dec 11 01:18:02 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 248b62
Dec 11 01:18:19 proxmox-prod03.sgdctroy.net corosync[3941]: [KNET ] link: host: 14 link: 0 is down
Dec 11 01:18:19 proxmox-prod03.sgdctroy.net corosync[3941]: [KNET ] host: host: 14 (passive) best link: 0 (pri: 1)
Dec 11 01:18:19 proxmox-prod03.sgdctroy.net corosync[3941]: [KNET ] host: host: 14 has no active links
Dec 11 01:18:19 proxmox-prod03.sgdctroy.net corosync[3941]: [KNET ] link: Resetting MTU for link 0 because host 14 joined
Dec 11 01:18:19 proxmox-prod03.sgdctroy.net corosync[3941]: [KNET ] host: host: 14 (passive) best link: 0 (pri: 1)
Dec 11 01:18:19 proxmox-prod03.sgdctroy.net corosync[3941]: [KNET ] pmtud: Global data MTU changed to: 1397
Dec 11 01:30:22 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 25726e
Dec 11 01:40:14 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 262273
Dec 11 01:47:42 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 26affb
Dec 11 02:35:15 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 2a172c
Dec 11 02:38:00 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 2a4923
Dec 11 03:30:23 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 2e1ca2
Dec 11 04:01:36 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 305aca
Dec 11 04:15:36 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 315c94
Dec 11 04:15:55 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 31627f
Dec 11 04:19:30 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 31a598
Dec 11 04:25:55 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 3218d2
Dec 11 04:39:14 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 3311fe
Dec 11 04:45:17 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 33808d
Dec 11 04:59:10 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 3480bb
Dec 11 05:21:26 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 361b63
Dec 11 05:44:05 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 37bc3e
Dec 11 05:47:00 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 37f023
Dec 11 06:02:57 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 391264
Dec 11 06:13:23 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 39d830
Dec 11 06:18:33 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 3a3368
Dec 11 06:18:33 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 3a338e
Dec 11 06:18:33 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 3a33e1
Dec 11 06:18:33 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 3a33ef
Dec 11 06:18:33 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 3a33f2
Dec 11 06:18:33 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 3a33f4
Dec 11 06:18:33 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 3a33f6
Dec 11 06:18:33 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 3a33f7
Dec 11 06:18:34 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 3a3425
Dec 11 06:18:34 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 3a3426
Dec 11 06:18:34 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 3a342e
Dec 11 06:18:38 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 3a34e4
Dec 11 06:18:38 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 3a34e6
Dec 11 06:18:38 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 3a353d
Dec 11 06:18:38 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 3a353e
Dec 11 07:33:53 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 3fa465
Dec 11 07:38:09 proxmox-prod03.sgdctroy.net corosync[3941]: [KNET ] link: host: 22 link: 0 is down
Dec 11 07:38:09 proxmox-prod03.sgdctroy.net corosync[3941]: [KNET ] host: host: 22 (passive) best link: 0 (pri: 1)
Dec 11 07:38:09 proxmox-prod03.sgdctroy.net corosync[3941]: [KNET ] host: host: 22 has no active links
Dec 11 07:38:11 proxmox-prod03.sgdctroy.net corosync[3941]: [KNET ] link: Resetting MTU for link 0 because host 22 joined
Dec 11 07:38:11 proxmox-prod03.sgdctroy.net corosync[3941]: [KNET ] host: host: 22 (passive) best link: 0 (pri: 1)
Dec 11 07:38:11 proxmox-prod03.sgdctroy.net corosync[3941]: [KNET ] pmtud: Global data MTU changed to: 1397
Dec 11 07:43:06 proxmox-prod03.sgdctroy.net corosync[3941]: [TOTEM ] Retransmit List: 404676