You're welcome! Yeah these things can be a bit (actually,
quite) annoying—especially in the case of SSDs. Sometimes these issues show up even when you think you've ruled every problem out through extensive testing and benchmarking. SSDs with a fast SLC cell cache and slow QLC cells otherwise are one of the things I personally really despise, because the device will tell the OS that the writes have been completed as soon as they land on the cache—even though the SSD will continue moving stuff from the cache to the actual storage in the background. So if your benchmark didn't run
long enough, you might not actually see the bottleneck appear. And once it appears, write performance just slows to a crawl.
Also, just to clarify here: Whether there's going to be any load on the
source of the backup (so, your PVE host / cluster) depends on several factors. For example, if your VM's disk is backed by a storage that uses HDDs, you might get quite a few hiccups inside the VM (file operations taking longer, etc.), as there is even more concurrent IO that the HDDs have to deal with. As another example, if the
target storage is slow, then backups will usually just take more time, I don't remember if there are any performance penalties on the source in that case (but I believe that there will be eventually, e.g. if the backup is made in "snapshot" mode; I actually never bothered to test this in detail myself).
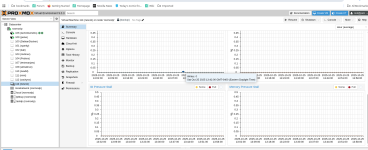
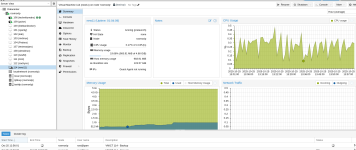
The network speed overall is bottlenecked by source and target storage bandwidth and latency, as well as the overall available network bandwidth (for the backup job) and latency. For example, let's say you have a beefy 25Gbit/s network interface, and you have a lightning-fast storage on your PBS host (the target) that can manage sustained random write loads with a bandwidth of 5GB/s (so, 40Gbit/s) without any issues. Now, if your source's storage can at most only offer read speeds at 250MB/s (so, 2Gbit/s), then the source's storage will be the bottleneck. So, when it comes to things like these, the slowest component will usually be the bottleneck.
(I apologize if you're aware of all of this by the way, I thought I might clarify all of this for other readers as well, in case they're not as familiar with this.)
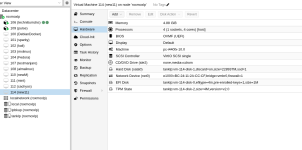
Ah, so if I understand correctly, you're mixing your HDDs and your SSD in your LVM setup? Yeah, that isn't too ideal. I'm not 100% sure how LVM handles this under the hood (and how it behaves in all the different ways you can configure that) but in most storage setups, you don't want to mix different "classes" of storage devices like that (with some tiny exceptions).
For example, if you have a mirror consisting of two devices, one of them being an HDD and the other an SSD, then most volume managers / filesystems will only report that a write operation has been completed if the data was written to both devices. So in that case, writes are bottlenecked by the HDD. Reads
can still be fast though, but I'm not sure if LVM automatically "understands" that one device is faster than the other.
So what I would personally recommend here is that you put your OS on the SSD alone and leave it in its own LVM pool or ZFS configuration. Using ZFS has the additional benefit that you can convert it into a mirror by adding another 500GB SSD later on, if you so wish. Otherwise, it's fine to stick with LVM. Then, put your primary datastore on a fast, enterprise-grade SSD. Alternatively, you can test if your current 2TB SSD works here too; if you do hit a bottleneck, it's
probably still not going to be as bad as your HDDs under load. So, you
might be able to get away with it. You'll have to test and measure, though.
Finally, configure the two HDDs in whatever way you'd like; those would then be your slower, secondary datastore that will be kept in sync with the primary one, but has higher rentention settings (since you have more space availabe). I can again recommend ZFS here, even for something like RAID-0 or RAID-1, because it makes it easier to tinker on your setup later (e.g. if you need to expand the storage of your secondary datastore).
Overall, I'm personally a big fan of ZFS for such setups, because—as I already mentioned—you can expand your ZFS pool later on if you so wish. So, if you set up your secondary datastore using a zpool with a mirror vdev (so, RAID-1 basically), and you find that it still is slow, you can still add a fast special device later on that stores the metadata for your pool. At least in the case of PBS, a lot of random IO is performed just for accessing metadata. (So, looking up chunks on the datastore, checking access times, etc. I could elaborate on this more, but this post is already long enough.

) Just ensure that your special device in ZFS is also mirrored, because if it dies, your pool's gone, too. Since that might become a bit expensive though (you'd need two new enterprise-grade SSDs for that), you at least can always do that later, or just not at all.
I hope that all of this helps (sorry for the wall of text)—there should be more around here in our forum regarding such setups if you sift through it a little.