Hello Team,
Trying to get the to bottom of underwhelming disk performance with ZFS, particularly random spikes of High IO wait.
I know this topic has been done to death, I've tried tuning parameters, I have CPU and RAM to spare, on SSD disks but I just can't work out why the whole server just chokes.
Dell R730 2 x Xeon E5-2698 v4, 512Gb RAM with LSI3008 IT mode firmware (H330?)
2 ZFS arrays
3 x Dell 400Gb SAS SSD - RAID Z1
4 x Crucial 4Tb SATA SSD - RAID Z2
Server consists mostly of containers with low load and a few Windows VMs, one of which is an MS Exchange server with 5 active users.
I have disabled swap on all Windows VMs and ensured sufficient memory allocation.
Almost all server reside on the SATA Z2 array.
Initially I thought the issue may have been high activity of small database writes for logs from unifi and uisp self hosted servers, so these were moved to the SAS Z1 array but there was no noticable change in performance.
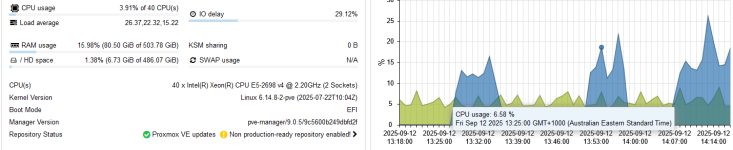
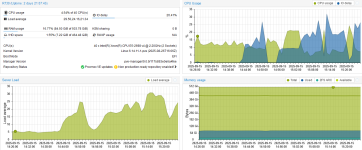
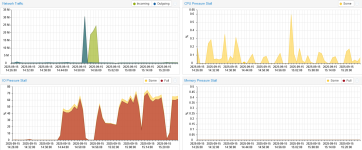
First screenshot shows idle server with random high IO spikes, last 3 screenshots show a windows update running on the exchange server bringing the whole server to a standstill while the CPUs are almost idle.
Thanks for any advice you can offer.
Trying to get the to bottom of underwhelming disk performance with ZFS, particularly random spikes of High IO wait.
I know this topic has been done to death, I've tried tuning parameters, I have CPU and RAM to spare, on SSD disks but I just can't work out why the whole server just chokes.
Dell R730 2 x Xeon E5-2698 v4, 512Gb RAM with LSI3008 IT mode firmware (H330?)
2 ZFS arrays
3 x Dell 400Gb SAS SSD - RAID Z1
4 x Crucial 4Tb SATA SSD - RAID Z2
Server consists mostly of containers with low load and a few Windows VMs, one of which is an MS Exchange server with 5 active users.
I have disabled swap on all Windows VMs and ensured sufficient memory allocation.
Almost all server reside on the SATA Z2 array.
Initially I thought the issue may have been high activity of small database writes for logs from unifi and uisp self hosted servers, so these were moved to the SAS Z1 array but there was no noticable change in performance.
First screenshot shows idle server with random high IO spikes, last 3 screenshots show a windows update running on the exchange server bringing the whole server to a standstill while the CPUs are almost idle.
Thanks for any advice you can offer.
")

