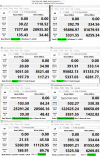
Due to my knowledge it is limited by the single-core-speed of the processor yet. I tested also using a NVMe,
Host:
Guest:
Samsung SSD 970 EVO Plus 500GB , which is unexpected slow in this test (QLC and big internal blocks maybe), so the VM is as fast as native. (Debian 12, AMD Ryzen)Host:
Code:
$ fio --filename=test --sync=1 --rw=randwrite --bs=4k --numjobs=1 --iodepth=4 --group_reporting --name=test --filesize=10G --runtime=300 --end_fsync=1 && rm test
test: (g=0): rw=randwrite, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=psync, iodepth=4
fio-3.33
Starting 1 process
test: Laying out IO file (1 file / 10240MiB)
note: both iodepth >= 1 and synchronous I/O engine are selected, queue depth will be capped at 1
Jobs: 1 (f=1): [w(1)][100.0%][w=588KiB/s][w=147 IOPS][eta 00m:00s]
test: (groupid=0, jobs=1): err= 0: pid=209549: Tue Nov 26 23:34:07 2024
write: IOPS=203, BW=816KiB/s (835kB/s)(239MiB/300002msec); 0 zone resets
clat (usec): min=1933, max=20006, avg=4900.50, stdev=1947.35
lat (usec): min=1933, max=20007, avg=4900.99, stdev=1947.47
clat percentiles (usec):
| 1.00th=[ 2704], 5.00th=[ 2769], 10.00th=[ 2802], 20.00th=[ 2900],
| 30.00th=[ 2999], 40.00th=[ 3195], 50.00th=[ 5866], 60.00th=[ 6259],
| 70.00th=[ 6456], 80.00th=[ 6587], 90.00th=[ 6915], 95.00th=[ 7177],
| 99.00th=[ 9634], 99.50th=[10945], 99.90th=[13566], 99.95th=[14222],
| 99.99th=[16450]
bw ( KiB/s): min= 520, max= 1448, per=100.00%, avg=816.48, stdev=328.66, samples=599
iops : min= 130, max= 362, avg=204.05, stdev=82.21, samples=599
lat (msec) : 2=0.01%, 4=46.87%, 10=52.38%, 20=0.75%, 50=0.01%
cpu : usr=0.17%, sys=1.79%, ctx=123590, majf=0, minf=9
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=0,61171,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=4
Run status group 0 (all jobs):
WRITE: bw=816KiB/s (835kB/s), 816KiB/s-816KiB/s (835kB/s-835kB/s), io=239MiB (251MB), run=300002-300002msec
Disk stats (read/write):
dm-6: ios=0/374388, merge=0/0, ticks=0/298244, in_queue=298244, util=94.44%, aggrios=74/437647, aggrmerge=0/0, aggrticks=40/402580, aggrin_queue=402720, aggrutil=94.29%
dm-0: ios=74/437647, merge=0/0, ticks=40/402580, in_queue=402720, util=94.29%, aggrios=74/424993, aggrmerge=0/12654, aggrticks=36/380708, aggrin_queue=492026, aggrutil=89.05%
nvme0n1: ios=74/424993, merge=0/12654, ticks=36/380708, in_queue=492026, util=89.05%Guest:
Code:
$fio --filename=test --sync=1 --rw=randwrite --bs=4k --numjobs=1 --iodepth=4 --group_reporting --name=test --filesize=10G --runtime=300 --end_fsync=1 && rm test
test: (g=0): rw=randwrite, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=psync, iodepth=4
fio-3.33
Starting 1 process
test: Laying out IO file (1 file / 10240MiB)
note: both iodepth >= 1 and synchronous I/O engine are selected, queue depth will be capped at 1
Jobs: 1 (f=1): [w(1)][100.0%][w=680KiB/s][w=170 IOPS][eta 00m:00s]
test: (groupid=0, jobs=1): err= 0: pid=757: Tue Nov 26 23:39:48 2024
write: IOPS=226, BW=906KiB/s (928kB/s)(265MiB/300005msec); 0 zone resets
clat (usec): min=1815, max=22301, avg=4411.09, stdev=1864.26
lat (usec): min=1815, max=22301, avg=4411.51, stdev=1864.31
clat percentiles (usec):
| 1.00th=[ 1991], 5.00th=[ 2073], 10.00th=[ 2147], 20.00th=[ 2245],
| 30.00th=[ 2638], 40.00th=[ 2868], 50.00th=[ 5342], 60.00th=[ 5473],
| 70.00th=[ 5735], 80.00th=[ 5932], 90.00th=[ 6259], 95.00th=[ 6587],
| 99.00th=[ 8979], 99.50th=[10290], 99.90th=[12387], 99.95th=[13173],
| 99.99th=[17695]
bw ( KiB/s): min= 558, max= 1928, per=99.98%, avg=906.95, stdev=415.05, samples=599
iops : min= 139, max= 482, avg=226.71, stdev=103.78, samples=599
lat (msec) : 2=1.21%, 4=41.35%, 10=56.85%, 20=0.59%, 50=0.01%
cpu : usr=0.11%, sys=1.59%, ctx=179539, majf=0, minf=10
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=0,67964,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=4
Run status group 0 (all jobs):
WRITE: bw=906KiB/s (928kB/s), 906KiB/s-906KiB/s (928kB/s-928kB/s), io=265MiB (278MB), run=300005-300005msec
Disk stats (read/write):
vdb: ios=16/206027, merge=29/142768, ticks=17/291859, in_queue=548255, util=96.05%