VictorSTS's latest activity
-
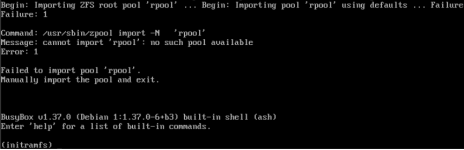
 VictorSTS posted the thread ZFS rpool isn't imported automatically after update from PVE9.0.10 to latest PVE9.1 and kernel 6.17 with viommu=virtio in Proxmox VE: Installation and configuration.On one of my training labs, I have a series of training VMs running PVE with nested virtualization. These VM has two disks in a ZFS mirror for the OS, UEFI, secure boot disabled, use systemd-boot (no grub). VM uses machine: q35,viommu=virtio for...
VictorSTS posted the thread ZFS rpool isn't imported automatically after update from PVE9.0.10 to latest PVE9.1 and kernel 6.17 with viommu=virtio in Proxmox VE: Installation and configuration.On one of my training labs, I have a series of training VMs running PVE with nested virtualization. These VM has two disks in a ZFS mirror for the OS, UEFI, secure boot disabled, use systemd-boot (no grub). VM uses machine: q35,viommu=virtio for... -
-
VictorSTS reacted to fweber's post in the thread [Feature request] Ability to enable rxbounce option in Ceph RBD storage for windows VMs with
 Like.
Hi, this should be resolved with Proxmox VE 9.1: When KRBD is enabled, RBD storages will automatically map disks of VMs with a Windows OS type with the rxbounce flag set, so there should be no need for a workaround anymore. See [1] for more...
Like.
Hi, this should be resolved with Proxmox VE 9.1: When KRBD is enabled, RBD storages will automatically map disks of VMs with a Windows OS type with the rxbounce flag set, so there should be no need for a workaround anymore. See [1] for more... -
VictorSTS replied to the thread [PROXMOX CLUSTER] Add NFS resource to Proxmox from a NAS for backup.It's unclear if you are using some VPN or direct connection using public IPs (hope not, NFS has no encryption), but maybe there's some firewall and/or NAT rule that doesn't allow RPC traffic properly? Maybe your synology uses some port range for...
-
VictorSTS reacted to bbgeek17's post in the thread [PROXMOX CLUSTER] Add NFS resource to Proxmox from a NAS for backup with Like.
There are two operations that are happening in the background when adding NFS storage pool in PVE: - health probe - mount When you are doing manual mount, the health probe is skipped. In PVE case the health probe is a "showmount" command...
-
VictorSTS reacted to t.lamprecht's post in the thread Proxmox Backup Server 4.1 released! with Like.
We're pleased to announce the release of Proxmox Backup Server 4.1. This version is based on Debian 13.2 (“Trixie”), uses Linux kernel 6.17.2-1 as the new stable default, and comes with ZFS 2.3.4 for reliable, enterprise-grade storage and...
-
VictorSTS replied to the thread Abysmally slow restore from backup.IIUC that patch seem to be applied to the verify tasks to improve it's performance. If that's the case, words can't express how eager am I to test it once patch gets packaged!
-
VictorSTS replied to the thread redundant qdevice network.This is wrong by design: you infrastructure devices must be 100% independent from your VMs. If your PVE hosts need to reach a remote QDevice, they must reach it on their own (i.e. run a wireguard tunnel on each PVE host). From the point of view...
-
VictorSTS replied to the thread Snapshots as Volume-Chain Creates Large Snapshot Volumes.IMHO, a final delete/discard should be done, too. If no discard is sent, it would delegate to the SAN what to do with those zeroes and depending on SAN capabilities (mainly thin provision but also compression and deduplication) may not free the...
-
VictorSTS replied to the thread PVE8to9 Prompts to Remove systemd-boot on ZFS & UEFI.It's explicitly explained in the PVE 8 to 9 documentation [1]: that package has been split in two on Trixie, hence systemd-boot isn't needed. I've upgraded some clusters already and removed that package when pve8to9 suggested to and the boot up...
-
VictorSTS replied to the thread Bug in wipe volume operation.I reported this already [1] and it is claimed to be fixed in PVE9.1 released today, although haven't tested it yet. [1] https://bugzilla.proxmox.com/show_bug.cgi?id=6941
-
VictorSTS reacted to t.lamprecht's post in the thread Proxmox Virtual Environment 9.1 available! with Like.
We're proud to present the next iteration of our Proxmox Virtual Environment platform. This new version 9.1 is the first point release since our major update and is dedicated to refinement. This release is based on Debian 13.2 "Trixie" but we're...
-
VictorSTS reacted to t.lamprecht's post in the thread Opt-in Linux 6.17 Kernel for Proxmox VE 9 available on test & no-subscription with Like.
We recently uploaded the 6.17 kernel to our repositories. The current default kernel for the Proxmox VE 9 series is still 6.14, but 6.17 is now an option. We plan to use the 6.17 kernel as the new default for the Proxmox VE 9.1 release later in...
-
The number of cluster members is an inexact limit. that ACTUAL limit has to do with how much data the cluster members have to keep synchronized- if each of your cluster members had 400vms with continuous api traffic- your cluster would probably...
-
VictorSTS replied to the thread Proxmox with 48 nodes.You need two corosync links. For 12 nodes on gigabit I would use dedicated links for both, just in case, even if having it just for Link0 would be enough. Max I've got in production with gigabit corosync is 8 hosts, no problems at all.
-
yes. you've already been given answers, you just dont like them. reinstall and restore from backup. fixing your install is more complicated and will require you to read documentation instead of just posting questions that are covered there.
-
VictorSTS replied to the thread Random freezes due to host CPU type.Given the logs you posted, I would start by removing docker from that host (it's not officially supported) and not exposing critical services like ssh to the internet. You also mention "VNC", which makes me think maybe you installed PVE on top of...
-
VictorSTS replied to the thread Suggestions for low cost HA production setup in small company.Why?
-
VictorSTS replied to the thread Suggestions for low cost HA production setup in small company.There is RSTP [1] Maybe, but it does allow to use both links simultaneously while on RTSP only one is in use and the other is fallback only. Which you should have anyway, connected to two switches with MLAG/stacking to avoid the network being...
-
VictorSTS replied to the thread Suggestions for low cost HA production setup in small company.If Ceph doesn't let you write is because some PG(s) don't have enough OSD to fulfill the size/min.size set on a pool. In a 3 host Ceph cluster, for that to happen you either have to: Lose 2 hosts: you won't have quorum neither on Ceph nor on PVE...
-
VictorSTS replied to the thread Proxmox Ceph Performance.That data means little if you don't post the exact fio test you ran. AFAIR, the benchmark that Ceph does is a 4k write bench to find out the IOps capacity of the drive. You should bench that with fio. Also, I would run the same bench on a...