superwinni2's latest activity
-
Ssuperwinni2 reacted to Bu66as's post in the thread PVE Umgebung und Guests teilweise nicht erreichbar - Logs? with
 Like.
EEE kannst du bei den I219 ruhig mit ausschalten, schadet nicht und hilft bei manchen Modellen zusätzlich gegen Link-Flaps. Bei den zickigen Intels lief bei mir beides zusammen (Offloads + EEE aus) am stabilsten. Die post-up Zeilen gehören ans...
Like.
EEE kannst du bei den I219 ruhig mit ausschalten, schadet nicht und hilft bei manchen Modellen zusätzlich gegen Link-Flaps. Bei den zickigen Intels lief bei mir beides zusammen (Offloads + EEE aus) am stabilsten. Die post-up Zeilen gehören ans... -
Ssuperwinni2 replied to the thread PVE Umgebung und Guests teilweise nicht erreichbar - Logs?.Die Sofortmaßnahme ist sofort aktiv. Das was man in /etc/network/interfaces einträgt sorgt dafür, dass nachdem das Interface "up" ist, dass der Befehl erneut ausgeführt wird.
-
Ssuperwinni2 replied to the thread Zwei OPNsense auf einem ProxmoxVE Host.Danke :) Wette hast du gewonnen ;) Und ich glaube das war der entsprechende Schuss damit ich es verstanden habe. Ich bin eben auf den Gedanken gekommen, dass ja der AdGuard auch viel mit dem Internet und somit mit der FW1 spricht. Jedoch...
-
Ssuperwinni2 reacted to Bu66as's post in the thread Zwei OPNsense auf einem ProxmoxVE Host with Like.
FDB-Overflow ist raus, gut. Dann müssen wir rausfinden warum die Bridge die MACs nicht dauerhaft lernt. Wenn das Flooding gerade aktiv ist, check mal ob die betroffene Client-MAC überhaupt in der FDB steht: bridge fdb show br vmbr001 | grep...
-
Ssuperwinni2 reacted to Bu66as's post in the thread Zwei OPNsense auf einem ProxmoxVE Host with Like.
Sehr schönes Debugging. Das Muster ist jetzt klar: MAC wird nach 300s gelöscht, erst ~10min später neu gelernt. Die Bridge lernt nur aus der SOURCE-MAC eingehender Frames. Dein AdGuard redet hauptsächlich mit Clients die am selben physischen...
-
Ssuperwinni2 replied to the thread Zwei OPNsense auf einem ProxmoxVE Host.Gleichzeitig nutzen kann man diese schon. Kommt eben ein bisschen aufs Routing an. So kann man mithilfe von Routen festlegen, dass wenn man auf das Netzwerk / VLAN 1,2,3,4,5,6,7,8 möchte, dass man als Router / Gateway die FW1 nutzen möchte...
-
Ssuperwinni2 replied to the thread Zwei OPNsense auf einem ProxmoxVE Host.@Bu66as MAC Adressen stehen (manchmal) in der FDB Datenbank. MAC learning ist überall auf "on". Zur besseren Auffindbarkeit mit "____": 5:enp27s0f0:<BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master vmbr001 state forwarding priority 32 cost 2...
-
-
Ssuperwinni2 replied to the thread Zwei OPNsense auf einem ProxmoxVE Host.Die FDB hat zwar einträge, jedoch noch lange in im Max bereich: root@pmfw1:~# bridge fdb show br vmbr001 | wc -l 437 root@pmfw1:~# cat /sys/class/net/vmbr001/bridge/hash_max 4096 Das Deaktivieren des floodings wäre vermutlich der Workaround...
-
Ssuperwinni2 replied to the thread Zwei OPNsense auf einem ProxmoxVE Host.Aging Time passt mit den 30000. Allerdings finde ich die lösung länger laufender ARP Einträge auch nicht sonderlich schön. root@pmfw1:~# cat /sys/class/net/vmbr001/bridge/ageing_time 30000 Das die Bridge aufgrund fehlender MAC/ARP Einträge das...
-
Ssuperwinni2 replied to the thread PVE Umgebung und Guests teilweise nicht erreichbar - Logs?.Was hast du für eine Netzwerkkarte verbaut? Falls es eine Intel E1000 Karte ist könnte das hier weiterhelfen: https://nb.balaji.blog/posts/fix-intel-e1000-proxmox-hang/
-
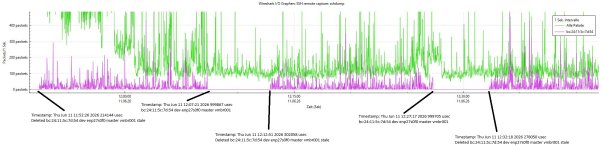
Ssuperwinni2 replied to the thread Zwei OPNsense auf einem ProxmoxVE Host.Das ganze hält auch nur eine kurze Begrenzte Zeit von ~ 290 Sekunden. Ich habe es hier mal mit Wireshark Visualisiert indem ich den bekannten Traffic rausgenommen habe. Da wo es so gut wie gegen 0 geht habe ich den "nmap arp scan" gemacht.
-
-
Ssuperwinni2 reacted to Falk R.'s post in the thread Zwei OPNsense auf einem ProxmoxVE Host with Like.
Ob du das virtuell oder Physisch betreibst ist erst einmal egal. Da würde ich mir mal die Carp Konfigurationen anschauen. Eigentlich sollte die interne FW nichts mitbekommen. Eventuell hast du auch etwas extremes Logging aktiv? Die beste Hilfe...
-
Ssuperwinni2 replied to the thread Zwei OPNsense auf einem ProxmoxVE Host.Das wäre auch meine Vermutung. Nur kann ich mir nicht erklären warum dem so ist. Ich betreibe inzwischen eine ganze Hand voll OPNsensen. Das ist der einzige Standort an dem ich ich aufgrund der Last das trennen sollte. In der Carp Konfiguration...
-
-
Ssuperwinni2 posted the thread Zwei OPNsense auf einem ProxmoxVE Host in Proxmox VE (Deutsch/German).Hallo Ich habe hier folgende Konstellation: Ich habe 2 Proxmox Hypervisoren. Auf jedem Hypervisor laufen 2 OPNsense VMs. Hypervisor PMFW1: FW1 FWInternBackup Hypervisor PMFW2: FW2 FWIntern Die FW1 ist mit FW2 eine Hochverfügbare Firewall...
-
Ssuperwinni2 replied to the thread Problem with worker VM start initiated by Veeam on PVE.Workaround with always running workers is running fine since. On my standalone PVE-Nodes I also have to leave them powered on. Tip: Set the "Start at boot" Option to enable. So you don't need to remember to start it up after updating or...
-
Ssuperwinni2 replied to the thread Problem with worker VM start initiated by Veeam on PVE.I am also experiencing the same issue with Worker VMs that fail to start. The problem only occurs on my Proxmox cluster nodes. On my standalone Proxmox VE node, the jobs have been running without any problems for over a year.