Hello!
I've had this issue on my home cluster since I built it in late 2019, but always figured it was caused by being on old/slow hardware and using a mixed bag of consumer SSD/HDDs...
~50MB/s is as good as I can get out of ceph write performance from any VM, to any pool type (SSD or HDD), on either of the following clusters.
Home cluster is a 4-node made from old supermicro fat twins with 2 X E5-2620 V2 and 80GB RAM per node. Ceph has a dedicated 1G Public network and dedicated 1G cluster network. 12 X 500GB SSDs (3 per node consumer drives) and 12 X 4TB HDDs (3 per node mixed blues and white labels, confirmed all conventional recording).
Work cluster is a 6-node made from supermicro 2113S-WTRT's with 1 X 7402P and 256GB RAM per node. Ceph has a dedicated 10G Public network and dedicated 10G cluster network. 24 X 2TB SSD's (4 X Kingston DC500R per node). 18 X 16TB HDD's (3 X Toshiba MG08ACA16TE per node). (the big spinners here are connected to each node via LSI SAS 9300-8e's in a 1-to-1 direct-attach (non-expander) enclosure.
Pools are configured with SSD/HDD "pool rules" per proxmox manuals on both clusters so that I can assign certain virtual disks to SSD only or HDD only storage. "write back" mode helped on the home cluster with continuous write performance from a truenas VM, bringing performance up to ~50MB/s, but at work our windows file server and pbs caps out around 50MB/s write regardless of cache settings on the virtual disk. It starts off a lot faster until the VM OS write cache fills up. The virtual disks are configured as virtio block devices in all cases.
This ~50MB/s cap is observed on virtualized Proxmox Backup, Windows Server, TrueNAS, Security Onion Sensors, etc. Doesn't matter if it's linux, unix, or windows.
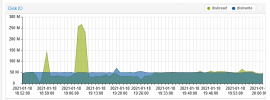
The file copy operations that are bringing things to a crawl here are not high "operation" workloads. These are just big video and zip/7z files being copied to disks hosted on the HDD pools. The ~50MB/s cap I'm observing on both of these clusters is in sequential write operations, not random/small-file. (It's much worse when random/small).
Home Cluster is on "free" repos and has been upgraded to Ceph Octopus (made no difference). Work cluster is on enterprise repos and still running Nautilus.
At home, 50MB/s is fine by me. I really don't care since it's just for personal file storage and this is plenty fast for us to share and backup files at small home-scale. I assumed this was to be expected with virtualization losses, overhead, slow old CPU's, slow network, and mixed bag of garbage drives.
At work, this is not acceptable. We need way more performance than 50MB/s here. Our internet connection is ~120MB/s :\ I have many TB's to move around and back up regularly. We're getting read to bring a lot more users into the domain hosted from this.
What's the trick? How do we speed this up? Need more OOOMF!!! lol
I've had this issue on my home cluster since I built it in late 2019, but always figured it was caused by being on old/slow hardware and using a mixed bag of consumer SSD/HDDs...
~50MB/s is as good as I can get out of ceph write performance from any VM, to any pool type (SSD or HDD), on either of the following clusters.
Home cluster is a 4-node made from old supermicro fat twins with 2 X E5-2620 V2 and 80GB RAM per node. Ceph has a dedicated 1G Public network and dedicated 1G cluster network. 12 X 500GB SSDs (3 per node consumer drives) and 12 X 4TB HDDs (3 per node mixed blues and white labels, confirmed all conventional recording).
Work cluster is a 6-node made from supermicro 2113S-WTRT's with 1 X 7402P and 256GB RAM per node. Ceph has a dedicated 10G Public network and dedicated 10G cluster network. 24 X 2TB SSD's (4 X Kingston DC500R per node). 18 X 16TB HDD's (3 X Toshiba MG08ACA16TE per node). (the big spinners here are connected to each node via LSI SAS 9300-8e's in a 1-to-1 direct-attach (non-expander) enclosure.
Pools are configured with SSD/HDD "pool rules" per proxmox manuals on both clusters so that I can assign certain virtual disks to SSD only or HDD only storage. "write back" mode helped on the home cluster with continuous write performance from a truenas VM, bringing performance up to ~50MB/s, but at work our windows file server and pbs caps out around 50MB/s write regardless of cache settings on the virtual disk. It starts off a lot faster until the VM OS write cache fills up. The virtual disks are configured as virtio block devices in all cases.
This ~50MB/s cap is observed on virtualized Proxmox Backup, Windows Server, TrueNAS, Security Onion Sensors, etc. Doesn't matter if it's linux, unix, or windows.
The file copy operations that are bringing things to a crawl here are not high "operation" workloads. These are just big video and zip/7z files being copied to disks hosted on the HDD pools. The ~50MB/s cap I'm observing on both of these clusters is in sequential write operations, not random/small-file. (It's much worse when random/small).
Home Cluster is on "free" repos and has been upgraded to Ceph Octopus (made no difference). Work cluster is on enterprise repos and still running Nautilus.
At home, 50MB/s is fine by me. I really don't care since it's just for personal file storage and this is plenty fast for us to share and backup files at small home-scale. I assumed this was to be expected with virtualization losses, overhead, slow old CPU's, slow network, and mixed bag of garbage drives.
At work, this is not acceptable. We need way more performance than 50MB/s here. Our internet connection is ~120MB/s :\ I have many TB's to move around and back up regularly. We're getting read to bring a lot more users into the domain hosted from this.
What's the trick? How do we speed this up? Need more OOOMF!!! lol

")
")