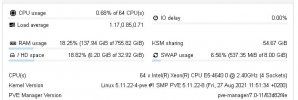
I have an Ubuntu 20.04.6 LTS VM:

Host is a Dell PowerEdge r820
4 X Intel(R) Xeon(R) CPU E5-4640 0 @ 2.40GHz
48 X 16gb dual rank 1333 MHz = 768 GB RAM
Promox - 5.11.22-4-pve #1 SMP PVE 5.11.22-8
the syslog on host:
Aug 17 23:16:24 novafreakvm kernel: mce: [Hardware Error]: Machine check events logged
Aug 17 23:16:24 novafreakvm kernel: Memory failure: 0x6887b73: Sending SIGBUS to kvm:1873892 due to hardware memory corruption
Aug 17 23:16:24 novafreakvm kernel: Memory failure: 0x6887b73: dirty LRU page still referenced by 1 users
Aug 17 23:16:24 novafreakvm kernel: Memory failure: 0x6887b73: recovery action for dirty LRU page: Failed
Aug 17 23:16:38 novafreakvm pvestatd[1734]: VM 100 qmp command failed - VM 100 qmp command 'query-proxmox-support' failed - got timeout
Aug 17 23:16:39 novafreakvm pvestatd[1734]: status update time (6.631 seconds)
The
journalctl -b -1 -e
Aug 17 17:43:48 plex snapd[809]: storehelpers.go:769: cannot refresh: snap has no updates available: "core", "core20", "lxd"
Aug 17 18:17:01 plex CRON[18148]: pam_unix(cron:session): session opened for user root by (uid=0)
Aug 17 18:17:01 plex CRON[18149]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)
Aug 17 18:17:01 plex CRON[18148]: pam_unix(cron:session): session closed for user root
Aug 17 19:17:01 plex CRON[19278]: pam_unix(cron:session): session opened for user root by (uid=0)
Aug 17 19:17:01 plex CRON[19279]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)
Aug 17 19:17:01 plex CRON[19278]: pam_unix(cron:session): session closed for user root
Aug 17 19:38:18 plex systemd[1]: Starting Daily apt download activities...
Aug 17 19:38:19 plex systemd[1]: apt-daily.service: Succeeded.
Aug 17 19:38:19 plex systemd[1]: Finished Daily apt download activities.
Aug 17 19:38:48 plex snapd[809]: storehelpers.go:769: cannot refresh: snap has no updates available: "core", "core20", "lxd"
Aug 17 20:17:01 plex CRON[20494]: pam_unix(cron:session): session opened for user root by (uid=0)
Aug 17 20:17:01 plex CRON[20495]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)
Aug 17 20:17:01 plex CRON[20494]: pam_unix(cron:session): session closed for user root
Aug 17 20:32:53 plex systemd[1]: Starting Message of the Day...
Aug 17 20:32:55 plex 50-motd-news[20829]: * Strictly confined Kubernetes makes edge and IoT secure. Learn how MicroK8s
Aug 17 20:32:55 plex 50-motd-news[20829]: just raised the bar for easy, resilient and secure K8s cluster deployment.
Aug 17 20:32:55 plex 50-motd-news[20829]: https://ubuntu.com/engage/secure-kubernetes-at-the-edge
Aug 17 20:32:55 plex systemd[1]: motd-news.service: Succeeded.
Aug 17 20:32:56 plex systemd[1]: Finished Message of the Day.
Aug 17 21:17:01 plex CRON[21668]: pam_unix(cron:session): session opened for user root by (uid=0)
Aug 17 21:17:01 plex CRON[21669]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)
Aug 17 21:17:01 plex CRON[21668]: pam_unix(cron:session): session closed for user root
Aug 17 22:17:01 plex CRON[22818]: pam_unix(cron:session): session opened for user root by (uid=0)
Aug 17 22:17:01 plex CRON[22819]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)
Aug 17 22:17:01 plex CRON[22818]: pam_unix(cron:session): session closed for user root
Aug 17 23:11:53 plex systemd[1]: Starting Refresh fwupd metadata and update motd...
Aug 17 23:11:53 plex systemd[1]: fwupd-refresh.service: Main process exited, code=exited, status=1/FAILURE
Aug 17 23:11:53 plex systemd[1]: fwupd-refresh.service: Failed with result 'exit-code'.
Aug 17 23:11:53 plex systemd[1]: Failed to start Refresh fwupd metadata and update motd.
Aug 17 23:17:01 plex CRON[23968]: pam_unix(cron:session): session opened for user root by (uid=0)
Aug 17 23:17:01 plex CRON[23969]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)
Aug 17 23:17:01 plex CRON[23968]: pam_unix(cron:session): session closed for user root
Aug 18 00:00:10 plex systemd[1]: Starting Rotate log files...
Aug 18 00:00:10 plex systemd[1]: Starting Daily man-db regeneration...
Aug 18 00:00:10 plex rsyslogd[807]: [origin software="rsyslogd" swVersion="8.2001.0" x-pid="807" x-info="https://www.rsyslog.com"] rsyslogd was HUPed
Aug 18 00:00:10 plex systemd[1]: logrotate.service: Succeeded.
Aug 18 00:00:10 plex systemd[1]: Finished Rotate log files.
Aug 18 00:00:11 plex systemd[1]: man-db.service: Succeeded.
Aug 18 00:00:11 plex systemd[1]: Finished Daily man-db regeneration.
Aug 18 00:15:49 plex systemd[1]: Starting Message of the Day...
Aug 18 00:15:50 plex 50-motd-news[25203]: * Strictly confined Kubernetes makes edge and IoT secure. Learn how MicroK8s
Aug 18 00:15:50 plex 50-motd-news[25203]: just raised the bar for easy, resilient and secure K8s cluster deployment.
Aug 18 00:15:50 plex 50-motd-news[25203]: https://ubuntu.com/engage/secure-kubernetes-at-the-edge
Aug 18 00:15:50 plex systemd[1]: motd-news.service: Succeeded.
Aug 18 00:15:50 plex systemd[1]: Finished Message of the Day.
Aug 18 00:17:01 plex CRON[25237]: pam_unix(cron:session): session opened for user root by (uid=0)
Aug 18 00:17:01 plex CRON[25238]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)
Aug 18 00:17:01 plex CRON[25237]: pam_unix(cron:session): session closed for user root
Aug 18 01:17:01 plex CRON[26426]: pam_unix(cron:session): session opened for user root by (uid=0)
Aug 18 01:17:01 plex CRON[26427]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)
Aug 18 01:17:01 plex CRON[26426]: pam_unix(cron:session): session closed for user root
Aug 18 02:13:48 plex snapd[809]: storehelpers.go:769: cannot refresh: snap has no updates available: "core", "core20", "lxd"
Aug 18 02:17:01 plex CRON[32886]: pam_unix(cron:session): session opened for user root by (uid=0)
Aug 18 02:17:01 plex CRON[32887]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)
Aug 18 02:17:01 plex CRON[32886]: pam_unix(cron:session): session closed for user root
Aug 18 03:10:01 plex CRON[33963]: pam_unix(cron:session): session opened for user root by (uid=0)
Aug 18 03:10:01 plex CRON[33964]: (root) CMD (test -e /run/systemd/system || SERVICE_MODE=1 /sbin/e2scrub_all -A -r)
Aug 18 03:10:01 plex CRON[33963]: pam_unix(cron:session): session closed for user root
Aug 18 03:17:01 plex CRON[34093]: pam_unix(cron:session): session opened for user root by (uid=0)
Aug 18 03:17:01 plex CRON[34094]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)
Aug 18 03:17:01 plex CRON[34093]: pam_unix(cron:session): session closed for user root
I have checked the HOST and no error in logs. I have 3 vms running on this host. One of them is running the exact same Ubuntu with same patch level that doies not crash. And what I mean by crash is that it is not even accessible via the console. I have to stop the VM because reboot fails in the promox.
Any help or push in the right direction would be greatly appreciated.
Thank you in advance.
Host is a Dell PowerEdge r820
4 X Intel(R) Xeon(R) CPU E5-4640 0 @ 2.40GHz
48 X 16gb dual rank 1333 MHz = 768 GB RAM
Promox - 5.11.22-4-pve #1 SMP PVE 5.11.22-8
the syslog on host:
Aug 17 23:16:24 novafreakvm kernel: mce: [Hardware Error]: Machine check events logged
Aug 17 23:16:24 novafreakvm kernel: Memory failure: 0x6887b73: Sending SIGBUS to kvm:1873892 due to hardware memory corruption
Aug 17 23:16:24 novafreakvm kernel: Memory failure: 0x6887b73: dirty LRU page still referenced by 1 users
Aug 17 23:16:24 novafreakvm kernel: Memory failure: 0x6887b73: recovery action for dirty LRU page: Failed
Aug 17 23:16:38 novafreakvm pvestatd[1734]: VM 100 qmp command failed - VM 100 qmp command 'query-proxmox-support' failed - got timeout
Aug 17 23:16:39 novafreakvm pvestatd[1734]: status update time (6.631 seconds)
The
journalctl -b -1 -e
Aug 17 17:43:48 plex snapd[809]: storehelpers.go:769: cannot refresh: snap has no updates available: "core", "core20", "lxd"
Aug 17 18:17:01 plex CRON[18148]: pam_unix(cron:session): session opened for user root by (uid=0)
Aug 17 18:17:01 plex CRON[18149]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)
Aug 17 18:17:01 plex CRON[18148]: pam_unix(cron:session): session closed for user root
Aug 17 19:17:01 plex CRON[19278]: pam_unix(cron:session): session opened for user root by (uid=0)
Aug 17 19:17:01 plex CRON[19279]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)
Aug 17 19:17:01 plex CRON[19278]: pam_unix(cron:session): session closed for user root
Aug 17 19:38:18 plex systemd[1]: Starting Daily apt download activities...
Aug 17 19:38:19 plex systemd[1]: apt-daily.service: Succeeded.
Aug 17 19:38:19 plex systemd[1]: Finished Daily apt download activities.
Aug 17 19:38:48 plex snapd[809]: storehelpers.go:769: cannot refresh: snap has no updates available: "core", "core20", "lxd"
Aug 17 20:17:01 plex CRON[20494]: pam_unix(cron:session): session opened for user root by (uid=0)
Aug 17 20:17:01 plex CRON[20495]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)
Aug 17 20:17:01 plex CRON[20494]: pam_unix(cron:session): session closed for user root
Aug 17 20:32:53 plex systemd[1]: Starting Message of the Day...
Aug 17 20:32:55 plex 50-motd-news[20829]: * Strictly confined Kubernetes makes edge and IoT secure. Learn how MicroK8s
Aug 17 20:32:55 plex 50-motd-news[20829]: just raised the bar for easy, resilient and secure K8s cluster deployment.
Aug 17 20:32:55 plex 50-motd-news[20829]: https://ubuntu.com/engage/secure-kubernetes-at-the-edge
Aug 17 20:32:55 plex systemd[1]: motd-news.service: Succeeded.
Aug 17 20:32:56 plex systemd[1]: Finished Message of the Day.
Aug 17 21:17:01 plex CRON[21668]: pam_unix(cron:session): session opened for user root by (uid=0)
Aug 17 21:17:01 plex CRON[21669]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)
Aug 17 21:17:01 plex CRON[21668]: pam_unix(cron:session): session closed for user root
Aug 17 22:17:01 plex CRON[22818]: pam_unix(cron:session): session opened for user root by (uid=0)
Aug 17 22:17:01 plex CRON[22819]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)
Aug 17 22:17:01 plex CRON[22818]: pam_unix(cron:session): session closed for user root
Aug 17 23:11:53 plex systemd[1]: Starting Refresh fwupd metadata and update motd...
Aug 17 23:11:53 plex systemd[1]: fwupd-refresh.service: Main process exited, code=exited, status=1/FAILURE
Aug 17 23:11:53 plex systemd[1]: fwupd-refresh.service: Failed with result 'exit-code'.
Aug 17 23:11:53 plex systemd[1]: Failed to start Refresh fwupd metadata and update motd.
Aug 17 23:17:01 plex CRON[23968]: pam_unix(cron:session): session opened for user root by (uid=0)
Aug 17 23:17:01 plex CRON[23969]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)
Aug 17 23:17:01 plex CRON[23968]: pam_unix(cron:session): session closed for user root
Aug 18 00:00:10 plex systemd[1]: Starting Rotate log files...
Aug 18 00:00:10 plex systemd[1]: Starting Daily man-db regeneration...
Aug 18 00:00:10 plex rsyslogd[807]: [origin software="rsyslogd" swVersion="8.2001.0" x-pid="807" x-info="https://www.rsyslog.com"] rsyslogd was HUPed
Aug 18 00:00:10 plex systemd[1]: logrotate.service: Succeeded.
Aug 18 00:00:10 plex systemd[1]: Finished Rotate log files.
Aug 18 00:00:11 plex systemd[1]: man-db.service: Succeeded.
Aug 18 00:00:11 plex systemd[1]: Finished Daily man-db regeneration.
Aug 18 00:15:49 plex systemd[1]: Starting Message of the Day...
Aug 18 00:15:50 plex 50-motd-news[25203]: * Strictly confined Kubernetes makes edge and IoT secure. Learn how MicroK8s
Aug 18 00:15:50 plex 50-motd-news[25203]: just raised the bar for easy, resilient and secure K8s cluster deployment.
Aug 18 00:15:50 plex 50-motd-news[25203]: https://ubuntu.com/engage/secure-kubernetes-at-the-edge
Aug 18 00:15:50 plex systemd[1]: motd-news.service: Succeeded.
Aug 18 00:15:50 plex systemd[1]: Finished Message of the Day.
Aug 18 00:17:01 plex CRON[25237]: pam_unix(cron:session): session opened for user root by (uid=0)
Aug 18 00:17:01 plex CRON[25238]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)
Aug 18 00:17:01 plex CRON[25237]: pam_unix(cron:session): session closed for user root
Aug 18 01:17:01 plex CRON[26426]: pam_unix(cron:session): session opened for user root by (uid=0)
Aug 18 01:17:01 plex CRON[26427]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)
Aug 18 01:17:01 plex CRON[26426]: pam_unix(cron:session): session closed for user root
Aug 18 02:13:48 plex snapd[809]: storehelpers.go:769: cannot refresh: snap has no updates available: "core", "core20", "lxd"
Aug 18 02:17:01 plex CRON[32886]: pam_unix(cron:session): session opened for user root by (uid=0)
Aug 18 02:17:01 plex CRON[32887]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)
Aug 18 02:17:01 plex CRON[32886]: pam_unix(cron:session): session closed for user root
Aug 18 03:10:01 plex CRON[33963]: pam_unix(cron:session): session opened for user root by (uid=0)
Aug 18 03:10:01 plex CRON[33964]: (root) CMD (test -e /run/systemd/system || SERVICE_MODE=1 /sbin/e2scrub_all -A -r)
Aug 18 03:10:01 plex CRON[33963]: pam_unix(cron:session): session closed for user root
Aug 18 03:17:01 plex CRON[34093]: pam_unix(cron:session): session opened for user root by (uid=0)
Aug 18 03:17:01 plex CRON[34094]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)
Aug 18 03:17:01 plex CRON[34093]: pam_unix(cron:session): session closed for user root
I have checked the HOST and no error in logs. I have 3 vms running on this host. One of them is running the exact same Ubuntu with same patch level that doies not crash. And what I mean by crash is that it is not even accessible via the console. I have to stop the VM because reboot fails in the promox.
Any help or push in the right direction would be greatly appreciated.
Thank you in advance.