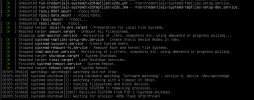
~# journalctl -b 0 -p 3
Feb 05 11:20:06 ProxHpDL380 kernel: [Firmware Bug]: the BIOS has corrupted hw-PMU resources (MSR 38d is 330)
Feb 05 11:20:08 ProxHpDL380 kernel: i8042: Can't read CTR while initializing i8042
Feb 05 11:20:06 ProxHpDL380 systemd-modules-load[1293]: Failed to find module 'vfio_virqfd #not needed if on kernel 6.2 or newer'
Feb 05 11:20:14 ProxHpDL380 pmxcfs[2740]: [quorum] crit: quorum_initialize failed: 2
Feb 05 11:20:14 ProxHpDL380 pmxcfs[2740]: [quorum] crit: can't initialize service
Feb 05 11:20:14 ProxHpDL380 pmxcfs[2740]: [confdb] crit: cmap_initialize failed: 2
Feb 05 11:20:14 ProxHpDL380 pmxcfs[2740]: [confdb] crit: can't initialize service
Feb 05 11:20:14 ProxHpDL380 pmxcfs[2740]: [dcdb] crit: cpg_initialize failed: 2
Feb 05 11:20:14 ProxHpDL380 pmxcfs[2740]: [dcdb] crit: can't initialize service
Feb 05 11:20:14 ProxHpDL380 pmxcfs[2740]: [status] crit: cpg_initialize failed: 2
Feb 05 11:20:14 ProxHpDL380 pmxcfs[2740]: [status] crit: can't initialize service
Feb 05 11:20:18 ProxHpDL380 smartd[2420]: Device: /dev/sdf [SAT], 341 Currently unreadable (pending) sectors
Feb 05 11:20:18 ProxHpDL380 smartd[2420]: Device: /dev/sdf [SAT], 340 Offline uncorrectable sectors
Feb 05 11:20:28 ProxHpDL380 pve-guests[2994]: CT is locked (disk)