this problem is similar to that of some other user here, but maybe they come from different issues.
I have 2 identical nodes, ibm x3650m2, with 20GB ram, 2x72 GB local disks (raid 1)
Disk /dev/sda: 72.0 GB, 71999422464 bytes
and both are connected to the same physical NAS:
vm disks from both nodes are on the same lvm/iscsi target
backups are made by both nodes on the same nfs share on the same NAS.
now, one node shows the problem, the other not :S
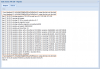
I noticed this problem from the web gui backup logs from that node, where I see that all (apparently successful) backups, since a while, start with something like
while the backup log sent by mail states (same exact job) but no "found duplicate" warning, so I never noticed from those...
all backups logs started on the other node are just fine, no "found duplicate" whatsoever.
digging the first node logs from the gui, all related logs show this, but since the email apparenly removed them, I never noticed.
(I could find other traces in other system logs perhaps? where?)
what can lead to this warning (?) what happened, how to solve?
more info: good node shows
bad node shows
those servers are not recently modified, and running pve since 1.5 and on NAS also nothing intentionally changed... and I see nothing strange...
currently both pve nodes have 3.1.24, are connected to the same gigabit switch, and have the same identical pveversions:
and similar pveperfs
Thanks,
Marco
I have 2 identical nodes, ibm x3650m2, with 20GB ram, 2x72 GB local disks (raid 1)
Disk /dev/sda: 72.0 GB, 71999422464 bytes
and both are connected to the same physical NAS:
vm disks from both nodes are on the same lvm/iscsi target
backups are made by both nodes on the same nfs share on the same NAS.
now, one node shows the problem, the other not :S
I noticed this problem from the web gui backup logs from that node, where I see that all (apparently successful) backups, since a while, start with something like
Code:
"INFO: Starting Backup of VM 102 (qemu)
INFO: status = running
INFO: update VM 102: -lock backup
[B]Found duplicate PV dB0Su2lTwsYfbcJPhby21PekoyeN3hHS: using /dev/sdc not /dev/sdb
Found duplicate PV dB0Su2lTwsYfbcJPhby21PekoyeN3hHS: using /dev/sdc not /dev/sdb[/B]
INFO: backup mode: snapshot
INFO: ionice priority: 7
INFO: creating archive '/mnt/pve/pve_ts879/dump/vzdump-qemu-102-2015_01_14-01_00_02.vma.lzo'
INFO: started backup task 'f373a23c-82d3-4cd6-a5af-382858f0ac91'
INFO: status: 0% (36044800/12884901888), sparse 0% (3534848), duration 3, 12/10 MB/s"while the backup log sent by mail states (same exact job) but no "found duplicate" warning, so I never noticed from those...
Code:
"102: Jan 14 01:00:02 INFO: Starting Backup of VM 102 (qemu)
102: Jan 14 01:00:02 INFO: status = running
102: Jan 14 01:00:03 INFO: update VM 102: -lock backup
102: Jan 14 01:00:03 INFO: backup mode: snapshot
102: Jan 14 01:00:03 INFO: ionice priority: 7
102: Jan 14 01:00:03 INFO: creating archive '/mnt/pve/pve_ts879/dump/vzdump-qemu-102-2015_01_14-01_00_02.vma.lzo'
102: Jan 14 01:00:04 INFO: started backup task 'f373a23c-82d3-4cd6-a5af-382858f0ac91'
102: Jan 14 01:00:07 INFO: status: 0% (36044800/12884901888), sparse 0% (3534848), duration 3, 12/10 MB/s"all backups logs started on the other node are just fine, no "found duplicate" whatsoever.
digging the first node logs from the gui, all related logs show this, but since the email apparenly removed them, I never noticed.
(I could find other traces in other system logs perhaps? where?)
what can lead to this warning (?) what happened, how to solve?
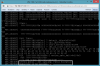
more info: good node shows
Code:
#ls /dev/sd*
/dev/sda /dev/sda1 /dev/sda2 /dev/sdb
#fdisk -l | grep "/dev/sd"
Disk /dev/mapper/pve-root doesn't contain a valid partition table
Disk /dev/mapper/pve-swap doesn't contain a valid partition table
Disk /dev/mapper/pve-data doesn't contain a valid partition table
Disk /dev/sdb doesn't contain a valid partition table
Disk /dev/sda: 72.0 GB, 71999422464 bytes
/dev/sda1 * 2048 1048575 523264 83 Linux
/dev/sda2 1048576 140623871 69787648 8e Linux LVM
Disk /dev/sdb: 1073.7 GB, 1073741824000 bytes
# pvscan
PV /dev/sdb VG pve_vm_disks_ts879 lvm2 [1000.00 GiB / 22.81 GiB free]
PV /dev/sda2 VG pve lvm2 [66.55 GiB / 8.37 GiB free]
Total: 2 [1.04 TiB] / in use: 2 [1.04 TiB] / in no VG: 0 [0 ]bad node shows
Code:
#ls /dev/sd*
/dev/sda /dev/sda1 /dev/sda2 /dev/sdb /dev/sdc
fdisk -l | grep "/dev/sd"
Disk /dev/mapper/pve-root doesn't contain a valid partition table
Disk /dev/mapper/pve-swap doesn't contain a valid partition table
Disk /dev/mapper/pve-data doesn't contain a valid partition table
Disk /dev/sdb doesn't contain a valid partition table
Disk /dev/sdc doesn't contain a valid partition table
Disk /dev/sda: 72.0 GB, 71999422464 bytes
/dev/sda1 * 2048 1048575 523264 83 Linux
/dev/sda2 1048576 140623871 69787648 8e Linux LVM
Disk /dev/sdb: 1073.7 GB, 1073741824000 bytes
Disk /dev/sdc: 1073.7 GB, 1073741824000 bytes
# pvscan
Found duplicate PV dB0Su2lTwsYfbcJPhby21PekoyeN3hHS: using /dev/sdc not /dev/sdb
PV /dev/sdc VG pve_vm_disks_ts879 lvm2 [1000.00 GiB / 22.81 GiB free]
PV /dev/sda2 VG pve lvm2 [66.55 GiB / 8.37 GiB free]
Total: 2 [1.04 TiB] / in use: 2 [1.04 TiB] / in no VG: 0 [0 ]those servers are not recently modified, and running pve since 1.5 and on NAS also nothing intentionally changed... and I see nothing strange...
currently both pve nodes have 3.1.24, are connected to the same gigabit switch, and have the same identical pveversions:
Code:
proxmox-ve-2.6.32: 3.1-114 (running kernel: 2.6.32-26-pve)
pve-manager: 3.1-24 (running version: 3.1-24/060bd5a6)
pve-kernel-2.6.32-19-pve: 2.6.32-96
pve-kernel-2.6.32-26-pve: 2.6.32-114
pve-kernel-2.6.32-11-pve: 2.6.32-66
lvm2: 2.02.98-pve4
clvm: 2.02.98-pve4
corosync-pve: 1.4.5-1
openais-pve: 1.1.4-3
libqb0: 0.11.1-2
redhat-cluster-pve: 3.2.0-2
resource-agents-pve: 3.9.2-4
fence-agents-pve: 4.0.0-2
pve-cluster: 3.0-8
qemu-server: 3.1-8
pve-firmware: 1.0-23
libpve-common-perl: 3.0-9
libpve-access-control: 3.0-8
libpve-storage-perl: 3.0-18
pve-libspice-server1: 0.12.4-2
vncterm: 1.1-6
vzctl: 4.0-1pve4
vzprocps: 2.0.11-2
vzquota: 3.1-2
pve-qemu-kvm: 1.4-17
ksm-control-daemon: 1.1-1
glusterfs-client: 3.4.1-1and similar pveperfs
Code:
pveperf /mnt/pve/pve_ts879/
CPU BOGOMIPS: 72530.88
REGEX/SECOND: 921498
HD SIZE: 11081.12 GB (ts879:/PVE)
FSYNCS/SECOND: 1567.25
DNS EXT: 260.35 ms
DNS INT: 1.33 ms (apiform.to.it)
root@pve2:~# pveperf /mnt/pve/pve_ts879/
CPU BOGOMIPS: 72530.88
REGEX/SECOND: 952254
HD SIZE: 11081.12 GB (ts879:/PVE)
FSYNCS/SECOND: 1601.93
DNS EXT: 199.14 ms
DNS INT: 1.08 ms (apiform.to.it)
Code:
pveperf /mnt/pve/pve_ts879/
CPU BOGOMIPS: 72531.60
REGEX/SECOND: 771375
HD SIZE: 11081.12 GB (ts879:/PVE)
FSYNCS/SECOND: 1343.58
DNS EXT: 49.35 ms
DNS INT: 1.03 ms (apiform.to.it)
root@pve1:~# pveperf /mnt/pve/pve_ts879/
CPU BOGOMIPS: 72531.60
REGEX/SECOND: 930701
HD SIZE: 11081.12 GB (ts879:/PVE)
FSYNCS/SECOND: 1638.08
DNS EXT: 163.32 ms
DNS INT: 0.95 ms (apiform.to.it)Thanks,
Marco